
Intro To Ranking Model Machine Learning
It is vital to perform ranking, given that different machine learning models perform differently on the same dataset. Additionally, different models address different business goals. Therefore, applying ranking helps to identify the best-performing model for a specific business goal.
Also, different machine learning performance measures are more appropriate in different scenarios than other metrics. For example, recall in one application is a better performance measure than accuracy. Therefore, ranking also provides a structured way to balance trade-offs, e.g., precision vs. recall.
If you’re new to machine learning or working with large datasets, consider starting with our Beginner’s Guide to Big Data for essential background on data handling and modeling at scale.
In an earlier article, we saw that relying solely on one evaluation metric can lead to misleading choices. Hence, a rigorous ranking process takes all these dimensions into account, including AUC, F1, and others. In turn, this enables choosing the right model that will positively impact operational outcomes, cost, and user experience. Furthermore, this ensures that the selected model better aligns with business priorities. This includes common business cases like fraud detection or churn reduction.
Another key benefit is that machine learning model ranking enables reproducibility and justification. It offers a transparent and auditable process for stakeholders that is helpful when presenting results to non-technical teams or executives.
What is model ranking in Machine Learning?
Machine learning model ranking is the process of ordering models in terms of their performance against predefined evaluation criteria. Different evaluation criteria are better suited for certain tasks than others, like accuracy, precision, recall, or AUC. That’s why model ranking indicates which models perform best in specific applications compared to other models.
Often, we are interested in the relative performance between models and prefer to compare models instead of just picking one. After ranking models based on business goals, we then select the top-ranked model for our particular application.
Consequently, we should apply ranking after training multiple models and objectively compare these models. Ranking is especially valuable during model tuning, ensemble creation, or when optimizing for different business metrics.
Specifically, model rankings depend on the prioritization of evaluation metrics, which form the basis of model rankings. These metrics include accuracy, F1 score, and AUC. Key influences on evaluation metric prioritization include the specific dataset and business context. Another important influence is performance constraints, such as speed or interpretability.
Depending solely on accuracy as an evaluation metric can lead to misleading results, especially with imbalanced datasets. Therefore, applying ranking with multiple metrics, such as precision, recall, and AUC, can provide a more comprehensive performance picture.
Common evaluation metrics
Binary Outcomes
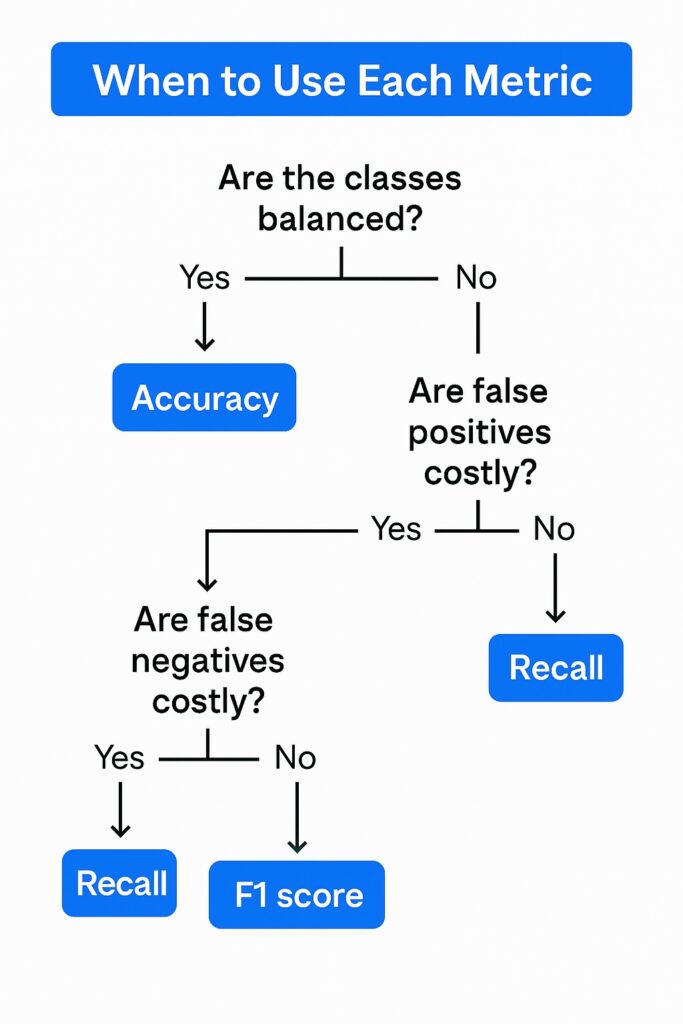
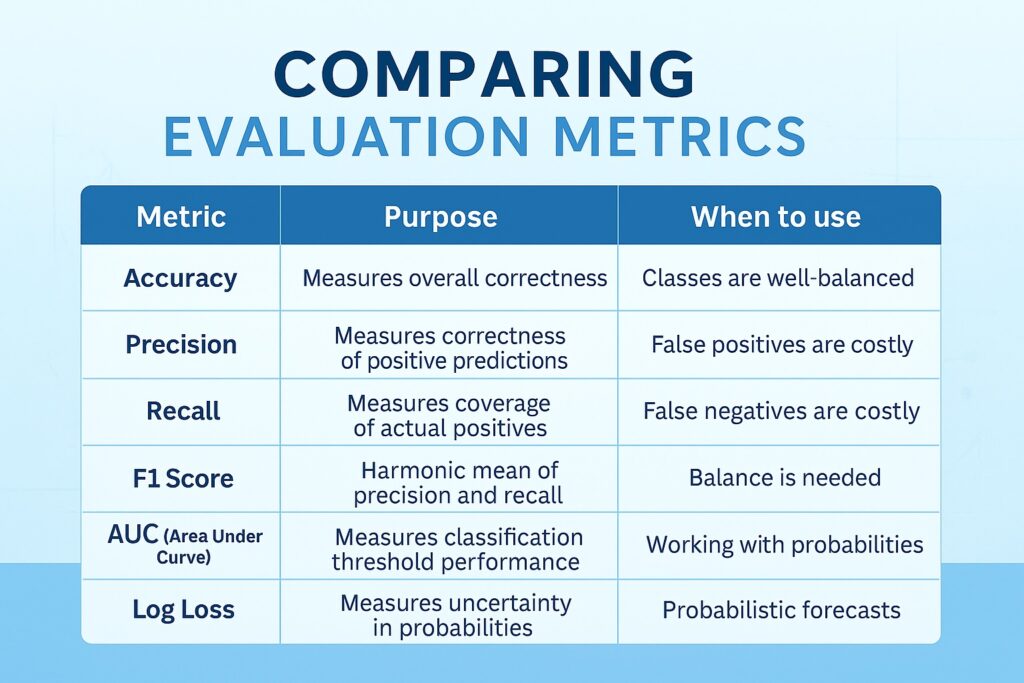
Accuracy is the most fundamental and simplest machine learning evaluation metric, measuring the proportion of correct predictions among all predictions. Subsequently, we can use it as a quick, performant benchmark, and it works well with balanced classes. However, whenever we have unbalanced classes then it can easily give misleading predictions. Therefore, we need to consider other metrics when classes are imbalanced. This also applies when one decision has more dire consequences than the other.
Whenever we have scenarios where false positives carry a high cost, like spam detection, then accuracy is a poor measure. Here we use precision that measures the proportion of predicted positives that are actually correct. In these scenarios, high precision means fewer false positives, which we want to minimize.
Conversely, there are applications where missing a positive case is costly, such as disease detection. Therefore, we should use recall, which measures the number of actual positive cases that were correctly identified. Subsequently, high recall means fewer false negatives, which we want to minimize in such scenarios.
Additionally, there are other scenarios with imbalanced datasets where we want to optimize between precision and recall. Therefore, we apply the F1, which is the harmonic mean of precision and recall. This enables us to utilize a single metric that balances false positives and false negatives, and is superior to accuracy in such cases.
Probabilistic Outcomes
While the F1 score is suitable for binary predictions, such as medical diagnoses, there are other scenarios where probabilistic thresholds are more valuable. These include applications like credit scoring, lead scoring, or risk ranking. Therefore, we use the Area Under the Receiver Operating Characteristic Curve (AUC-ROC). This evaluates a model’s ability to distinguish between classes across all thresholds. Hence, a high AUC means better model performance in ranking positive instances higher than negative ones. It is threshold-independent, making it helpful in comparing classifiers objectively.
There are scenarios like risk assessment, where overconfident, wrong predictions are dangerous. A suitable evaluation metric is log loss, which measures the uncertainty of a model’s probability estimates. Here, it penalizes confident but incorrect predictions more heavily than less certain ones.
Summary
In summary, we use accuracy when classes are well-balanced and all errors carry equal weight. Whenever false positives are costly, we should use precision. Otherwise, if false negatives are costly, we should use recall. However, when we need to strike a balance between precision and recall, we use the F1 score. Finally, whenever we work with probabilistic outputs or model ranking then we should use AUC or Log Loss.
Model Ranking Techniques and Frameworks for Machine Learning
We have finally reached a point where we can apply machine learning to ranking models. This allows us to select the optimal model. We explore ranking techniques that we use to evaluate and compare multiple learning models. These rely on selected performance metrics like accuracy, F1 score, or AUC that we covered earlier. Therefore, we can identify which model is best suited for a specific task or goal.
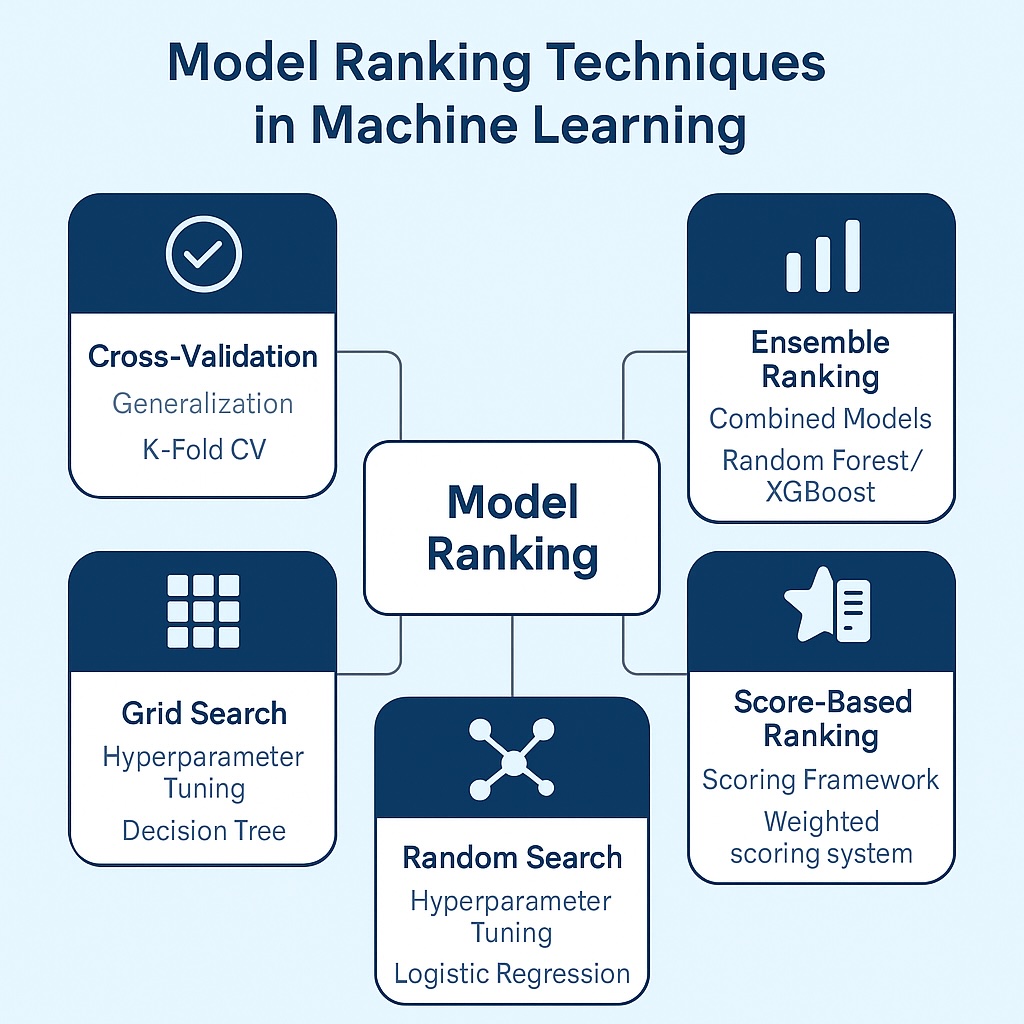
Specifically, we use cross-validation to perform our ranking by splitting the dataset into multiple training and testing subsets. Next, we evaluate each model across these splits to ensure consistency with our evaluations. This ensures that our ranking reflects performance that generalizes to unseen data, especially important for overfitting models.
Hyperparameter selection is also critical for model ranking. Therefore, grid search is a ranking technique that tests all possible combinations of hyperparameters within a defined range. Conversely, the random search technique samples a subset of hyperparameter combinations randomly. However, both these techniques rank models across different hyperparameter settings.
Whereas grid search and random techniques select single models, in contrast, ensemble techniques combine multiple models to improve overall performance. Therefore, they evaluate and rank candidate models before including them in any deployment. This ensures that only the top-ranked base learners are selected for the final ensemble.
Score-based ranking simplifies decision-making by standardizing metrics into a single score. It converts model evaluation metrics into numeric scores, allowing for easy comparison. Therefore, each model receives a score for metrics like accuracy, recall, or AUC. Also, we can perform customized weighting, letting us prioritize business-specific goals like precision over recall. Subsequently, we rank our models based on their total or weighted score.
Weighted Scoring
Several of these frameworks can utilize weighted scoring that assigns different importance levels to each evaluation metric. This allows these frameworks to reflect domain-specific needs, such as favoring recall in medical diagnosis or precision in fraud detection. Frameworks that benefit from this include score-based ranking, cross-validation, and hyperparameter search.
Model Ranking
Having explored ranking frameworks, we must ensure that they accurately reflect the specific objectives of the business or applications. Additionally, we must recognize that different goals, such as fraud detection or customer retention, necessitate different evaluation priorities. Subsequently, we should choose metrics that are based on the real-world impact of prediction errors. Furthermore, we need to consider operational constraints like latency, interpretability, or resource usage. Our goal is to produce a will-aligned framework that ensures the chosen technique performs effectively in its intended environment.
Business implications or use cases
Now that we have a framework around ranking machine learning models, we want to consider applying this to real-world use cases. Specifically, each business has unique operational goals and acceptable levels of risk. Therefore, we use model ranking to compare performance based on those specific priorities. This will ensure the selected model supports both business outcomes and risk management, and we will consider some everyday use cases.
Many businesses are subjected to fraud, causing financial losses, and therefore need a highly accurate model. Fraud detection models must strike a balance between detection and false alarm rates. Consequently, we should apply model ranking to select a model that has the best performance in both precision and recall.
Most businesses aim to ensure customer retention and respond to customer churn in a timely manner. Therefore, they want to identify at-risk customers early to predict customer churn effectively. Consequently, detecting at-risk customers is crucial, even if it results in false alarms.
Therefore, we apply ranking to select the model that best predicts churn with high recall.
Another everyday use case for retail businesses is recommendation systems that personalize the customer shopping experience. Retailers want to reduce showing customers irrelevant products and use ranking to select performance based on precision.
An important use case in healthcare is detecting critical conditions where missed diagnoses can lead to serious or fatal consequences. Subsequently, we want a ranking that prioritizes models that minimize false negatives to avoid missed diagnoses. This will lead to better patient outcomes with more reliable clinical decision support.
Ranking Model Machine Learning Best practices & Pitfalls
Several guidelines will help in effectively evaluating different models. Firstly, we should always align our ranking metrics with our business objectives, rather than simply focusing on model accuracy. Often in the real world, we encounter imbalanced datasets, which means we should avoid relying on a single evaluation metric. Another critical pitfall is overfitting, and we should validate model rankings with cross-validation.
Conclusion
Model performance is dictated by business goals that have unique use cases. Simple model accuracy is often a poor performance measure, and we should rank models across more commensurate measures of performance. We have provided a survey of such techniques, equipping the reader to explore these in more detail.
Further Reading
Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow (3rd Edition)
Aurélien Géron
Interpretable Machine Learning: A Guide for Making Black Box Models Explainable
Christoph Molnar
Pattern Recognition and Machine Learning
Christopher M. Bishop
Disclosure: This post contains affiliate links. If you click and purchase, we may receive a small commission at no extra cost to you. As an Amazon Associate, we earn from qualifying purchases.