
Introduction
This guide defines a security incident in AWS as any event threatening the confidentiality, integrity, or availability of cloud resources necessitating an adequate response. Common examples of these events include unauthorized access, leaked or compromised IAM credentials, and privilege misuse. Other examples may involve malicious activity such as malware deployment, data exfiltration, or unusual network traffic patterns.
Cloud computing’s core advantage is scalability, which brings with it the risk of security incidents spreading faster than in traditional data centers. Additionally, many organizations that leverage AWS must meet stringent compliance and regulatory requirements. Therefore, it is essential to minimize damage from security incidents and maintain customer trust through effective incident response.
Dire consequences can result from uncontained incidents, including costly downtime and disrupted operations. Additionally, financial losses can ensue arising from data theft, fraud, or ransom demands. Furthermore, regulatory fines can follow since regulatory bodies are increasing their oversight of cybersecurity. However, far more damaging is reputational harm far outlasts the immediate technical issue.
AWS to the rescue, since it also provides detection services like GuardDuty and CloudTrail to spot any suspicious activity. Along with these sentinels, AWS also enables automated response by offering services like EventBridge and Lambda functions. Another essential service in the AWS Security Response armory is Security Hub, which centralizes alerts to help teams prioritize and act quickly.
This guide provides a structured approach for responding to security incidents in AWS. Furthermore, it covers each stage of security incident response within AWS from detection through to recovery and remediation. Therefore, the goal of this guide is to help teams strengthen their cloud defenses and act with confidence.
What Is AWS Security Incident Response?
Definition and Scope
AWS security incident response is the structured process of managing and resolving threats in the cloud, which this guide covers. Therefore, its focus is on protecting the confidentiality, integrity, and availability of AWS resources that organizations are leveraging. This is crucial since it allows organizations to align with the AWS shared responsibility model. Furthermore, incident responses span detection, containment, eradication, recovery, and post-incident review.
Cloud vs. Traditional Environments
Given the elastic scaling and automation nature of AWS and other public cloud environments, incidents can spread rapidly. This is in contrast to traditional on-premises environments, where their response methodology does not map directly to cloud environments. Also, incident response in AWS requires integrating multiple services (e.g., GuardDuty, CloudTrail, Security Hub), making it fundamentally different from traditional on-premises methods. Finally, automated responses are far more effective than manual processes, as explored in Automated Incident Response in AWS: Best Practices and Tools.
Key Characteristics
There are details on AWS environments highlighting their need for incident response that differ from on-premises environments. AWS environments are highly fluid with dynamic resources that can quickly disappear, necessitating prompt responses. Also, the availability of centralized logging provides detailed event histories for forensics. Additionally, security groups offer the ability to achieve network isolation. Another AWS service that plays a critical role in containment is Identity and Access Management (IAM).
Examples of Security Incidents in AWS Necesitating Response
There are several incidents in AWS whose response differs from on-premises, as explained by this guide. Since AWS provides the IAM service, unauthorized IAM activity, such as exploiting API keys, is unique to AWS. Another significant AWS service is S3, where publicly exposed buckets may lead to data leaking. GuardDuty is a critical service that alerts to any malware and, even more seriously, crypto-mining behavior. Many AWS environments manage cross-region traffic, where there is the opportunity for malicious actors to perform data exfiltration.
Why AWS Security Incident Response Matters for Cloud Security
This guide has shown how AWS cloud differs from on-premises environments and that rapid detection and incident response reduce the impact of cloud threats. It is also critical for strong processes that ensure compliance with global regulators. Also, this builds confidence with AWS customers through tested response playbooks. Therefore, a well-designed incident response program strengthens overall resilience.
Core Principles of Incident Response in AWS
There are several core principles this guide discusses in preparing an effective security incident response in AWS that practitioners should follow.
Preparedness and Planning
Effective security response in AWS always begins with predefined playbooks and runbooks for conducting responses to security events. However, security teams should rehearse these guided responses through simulations and “game days”. Therefore, they are fully prepared in the event of an incident. Furthermore, playbooks should embed automation wherever possible to reduce manual delays and operational errors. Another consideration is enabling multi-account planning for better AWS resource isolation.
Visibility and Logging
Centralized logging and visibility are essential for security incident response, as organizations often span multiple accounts and AWS Organizations. AWS CloudTrail provides a centralized location for a complete audit trail of all these accounts. Both GuardDuty and Security Hub enable centralized visibility by correlating alerts. AWS CloudWatch provides metrics and alarms that track anomalies in real time. Furthermore, implementing log retention policies is vital to ensure that data is available for investigators.
Identity and Access Control
Containment of events is fundamental to AWS security incident response, and IAM least privilege is the foundation for effective containment. Containment is supported by role-based access, which enables controlled and auditable interventions. Additionally, temporary credentials reduce exposure whenever keys are compromised, further strengthening containment. Whenever there are attempts to escalate privilege, it is crucial to monitor these activities continuously.
Automation and Orchestration
Automated Incident Response in AWS: Best Practices and Tools discussed the vital role of automation for security incident responses. It highlighted the essential role of EventBridge, which routes alerts to Lambda for near real-time response. Additionally, automated remediation minimizes downtime and reduces the window of opportunity for attackers compared to manual incident responses. Systems Manager also supports incident response orchestration by executing runbooks across fleets of resources. Another critical benefit of consistent automation is that it reduces human error during high-stress incidents.
Post-Incident Learning
To really make AWS security response effective, it is essential to incorporate lessons learnt into future playbooks. Therefore, a root cause analysis should always be conducted at the conclusion of every incident. Additionally, security teams should feed back findings into improved security posture and controls. Also, diligent reporting supports compliance and audit readiness, especially in stringent regulatory environments. In conclusion, lessons learnt strengthen preparedness for future threats.
Step-by-Step AWS Security Incident Response Guide
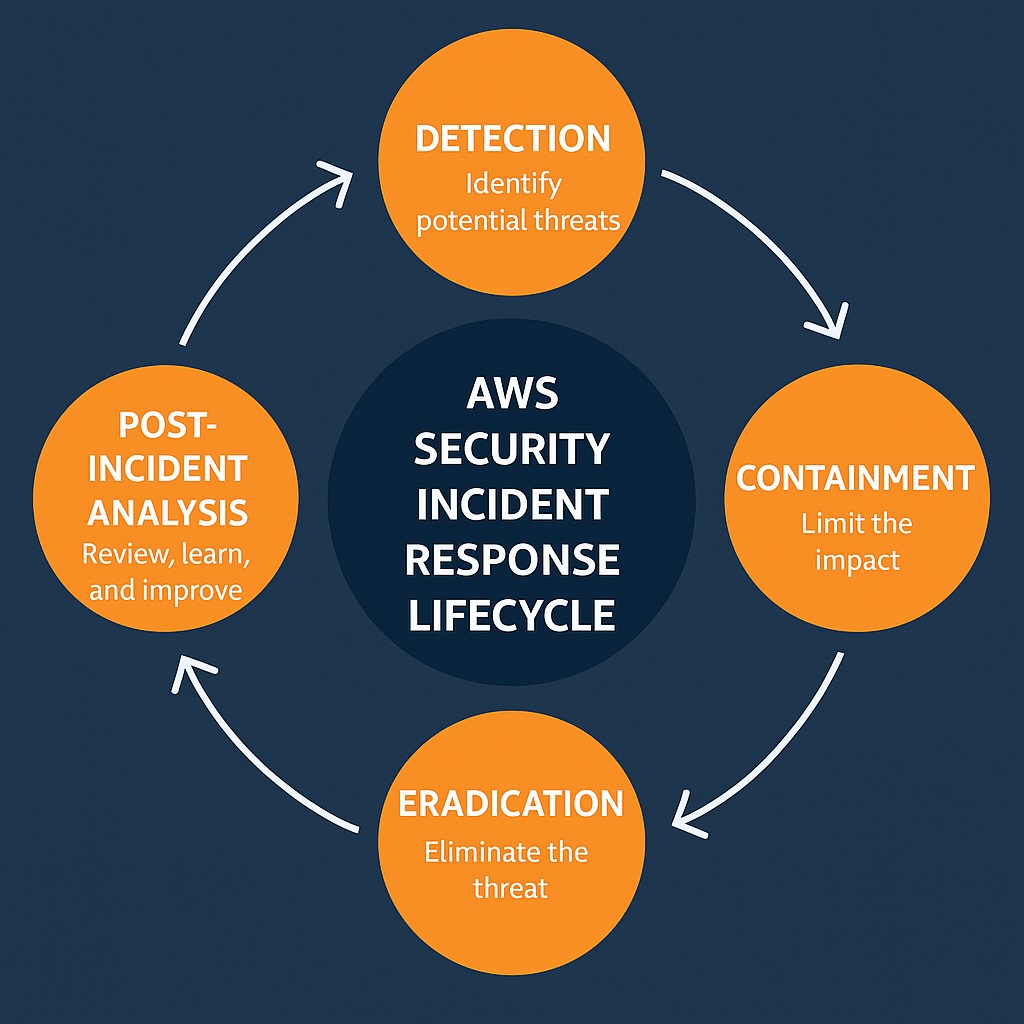
Step 1 – Detection
Monitoring with Core AWS Services
Several core AWS services continuously monitor security events across all accounts. CloudWatch monitors metrics associated with AWS resources, such as CPU utilization, and triggers alerts for any anomalies that exceed a threshold. CloudTrail complements CloudWatch by logging all API calls and account activity, providing audit trails for downstream analysis. GuardDuty applies to ML and threat intelligence to monitor logs and network traffic to identify malicious or unauthorized activity.
Aggregating and Centralizing Findings
Security events occur across hundreds of accounts, necessitating centralized monitoring and management. Security Hub consolidates alerts from core AWS services that monitor security events in their respective accounts. Therefore, it complements the other security services by providing a cross-account dashboard that displays consolidated findings from all member accounts. This enables security teams to view and prioritize organization-wide alerts without needing to switch accounts.
Automating Alerts
Manual response alerts from consolidated monitoring services are too slow and error-prone for modern cloud architectures. Automated responses with human oversight are optimal for effective response to malicious or unauthorized security events. EventBridge is the core service that routes suspicious activity alerts in real-time for automated responses. Lambda functions are the workhorses in triggering automated responses to security events, such as quarantining resources. SNS handles the notification of security teams of critical security events.
Step 2 – Containment for AWS Security Incident Response Covered by this Guide
Just as health workers quarantine physical diseases, this AWS security incident response guide recommends quarantining or containing compromised resources.
Identity and Access Restrictions
Security engineers must ensure that compromised access mechanisms are immediately revoked, and this includes IAM keys and credentials. An essential practice is also to ensure that access follows the principle of least privilege to limit unauthorized access. This is achieved by applying least privilege IAM policies. Whenever emergency interaction is needed, security engineers should always enforce role-based access.
Network Isolation
Compromised AWS resources can potentially inflict grave damage, and isolating them is of paramount importance. A prime example is EC2 instances, where security engineers can isolate by applying security groups to these instances. Another defense in depth is applying NACL rules that restrict any malicious traffic. The next level of defense is VPCs that segment, isolate, and prevent critical AWS workloads from malicious activities.
Limiting Blast Radius
Ultimately, whenever a resource or network is compromised, security engineers want to limit the blast radius of the effect on other resources or networks. AWS service control policies play an important role here by restricting account permissions to resources and actions. Security engineers should also tag resources for containment workflow and tracking. Additionally, they should apply temporary restrictions allowing for a deeper investigation into security events.
Step 3 – Eradication and Recovery
Once a compromised resource is quarantined, security engineers rectify the security issue and ensure infrastructure recovery.
Removing Threats
Once a compromised resource is identified and quarantined, then security engineers must repair that resource. The first step is to terminate the instance immediately to prevent any further damage. Security engineers should then replace any compromised workloads with a clean and patched AMI. Whenever there is an identification of any malicious code or scripts within the environment, then security engineers must ensure their removal either by automated or manual means. Finally, security engineers must ensure the revocation of any compromised security credentials for tokens to prevent reinfection.
Restoring Systems
Security events and their response often cause system degradation, and security engineers must ensure prompt system recovery. There are two main recovery categories, data and infrastructure. Data recovery typically involves recovering data from encrypted S3 backups or from EBS snapshots. This also consists of ensuring data integrity before reintroducing it into production. To reintroduce a secure infrastructure, it is recommended that security engineers leverage services such as CloudFormation or IaC templates.
Validating Security Posture
Once engineers have completed system restoration, they must ensure that there is no degradation of its security posture. Also, they aim to enhance security posture. They should patch any vulnerabilities that they identified during the investigation. Additionally, they need to confirm that there are no lingering exposures by using the AWS Inspector service. Furthermore, they should actively search for vulnerabilities through penetration testing, which primarily depends on human skills coupled with automated processes.
Step 4 – Post-Incident Analysis
The cybersecurity environment landscape is continually changing, and AWS security incident response needs to adapt constantly. Handling security events requires constant improvement, which can be achieved by learning from past incidents.
Root Cause and Documentation
Whenever a security incident occurs, security engineers must identify and rectify the vulnerability through adjustments to system architecture or by implementing new practices. The first step is to perform root cause analysis, allowing them to identify system weaknesses and vulnerabilities. They are also required to record incident details for audit purposes and adhere to regulatory compliance. Organizations should also provide complete visibility to leadership and stakeholders by sharing all findings.
Updating Playbooks
No security incident response playbook is perfect despite the best efforts, and continual improvement is mandatory. Security teams must update runbooks with lessons learned from incident postmortems. Additionally, whenever security teams identify any gaps, they should expand the automated responses to address these gaps. Furthermore, they should adjust IAM, logging, and monitoring rules as needed, as per any findings from security incident postmortems.
Strengthening Preparedness
Security teams should continually enhance their preparedness, especially in response to an incident. Once they have made improvements to their runbooks and expanded their automated response, they should conduct post-incident simulations to test these improvements. They should also ensure that their practices are aligned with the AWS Well-Architected Security Pillar. Furthermore, they must have complete transparency on any incidents and their resolution to build organizational confidence.
AWS Security Tools and Services for Incident Response Covered by this Guide
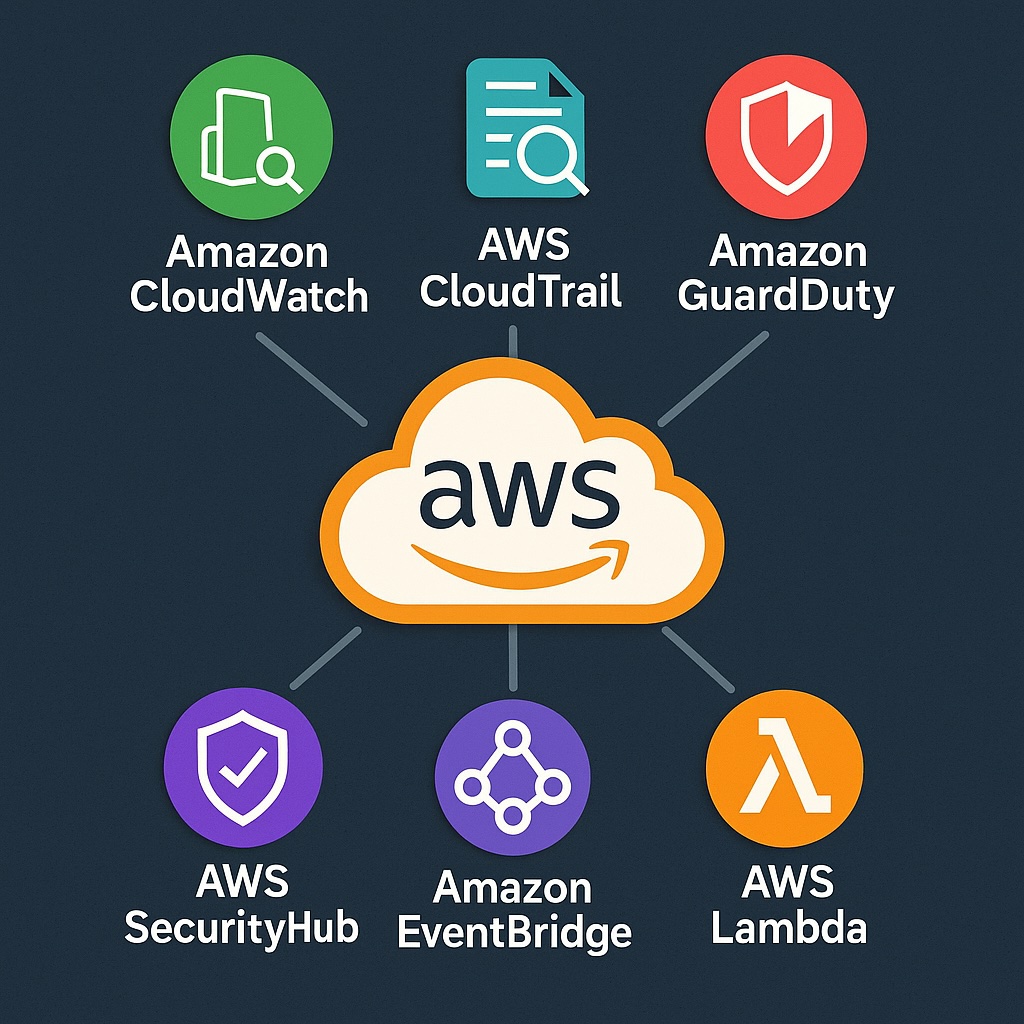
There is a core set of AWS services that support security incident response that this guide highlights.
Amazon CloudWatch – Metrics and Operational Insight
Monitoring is the first stage of any security incident response posture because most incidents manifest themselves through metrics. Amazon CloudWatch monitors these metrics, enabling early detection of incidents through potential performance or metrics anomalies. These typically include system-level performance metrics such as CPU, latency, and network activity. The CloudWatch service allows security engineers to create alarms that trigger automated responses through EventBridge or Lambda.
AWS CloudTrail – Comprehensive Audit Logging
Alongside monitoring, logging is also a primary component of any security incident response posture. This is because any malicious activity is invariably identifiable through API calls and user actions across AWS actions that AWS CloudTrail records. Other AWS services, such as GuardDuty, use these records for behavior-based threat detection. Equally valuable, these logs support investigation by providing detailed event history for every account. When these are integrated with CloudWatch and S3, they enable governance and forensic analysis.
AWS EventBridge and Lambda – Automated Security Incident Response Backbone Guide
CloudWatch and CloudTrail collect security event data, and CloudWatch uses alerts to trigger responses. However, EventBridge and Lambda perform actual automated responses to these alerts. EventBridge acts as the routing layer for real-time security handling, whereas Lambda executes custom remediation logic such as isolating instances or revoking credentials. Hence, they complement each other in forming the foundation for automated response pipelines. Furthermore, by providing an automated response pipeline, they reduce human error and accelerate time-to-response for security teams.
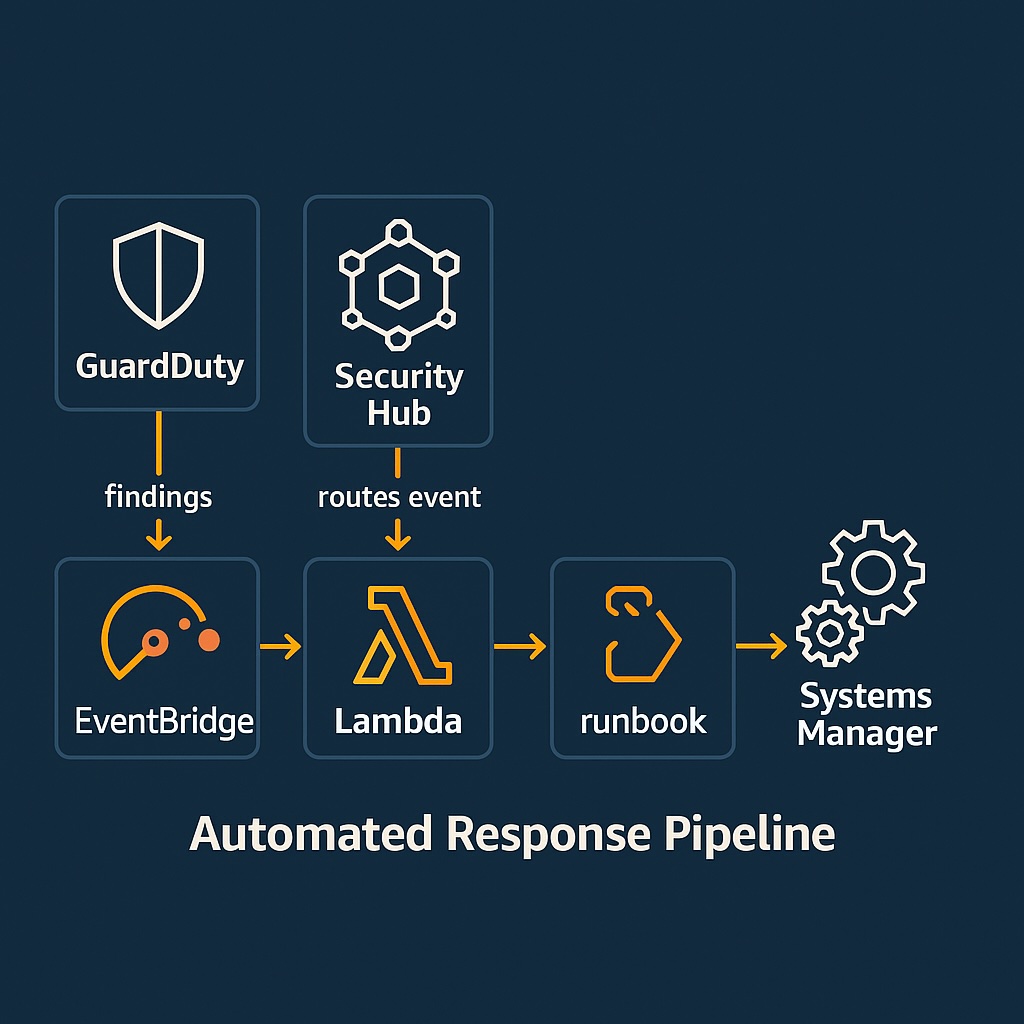
Amazon GuardDuty – Intelligent Threat Detection
The above services working together provide automated handling of a large category of security events based on logical algorithms or a formulaic approach. GuardDuty augments this approach by continuously monitoring collected security event data for deeper insights into suspicious or malicious activity. This is data collected by CloudWatch and CloudTrail and includes AWS account activity and network traffic. Here, GuardDuty uses machine learning and threat intelligence feeds to detect anomalies like compromised credentials or crypto-mining. It then generates actionable security findings that integrate with Security Hub and EventBridge.
AWS Security Hub – Centralized Security Visibility for Incident Response Guide
The services this guide has covered so far work well in complementing each other; however, they often operate over hundreds of accounts. Therefore, security teams use AWS Security Hub to aggregate the findings from services like GuardDuty, Inspector, Config, and third-party integrations. It also provides security teams with a cross-account, multi-region dashboard for organization-wide visibility. Additionally, it uses the AWS Security Finding Format as a consistent schema for normalizing and prioritizing findings. Furthermore, it integrates with automation services for streamlined remediation workflows.
AWS Systems Manager – Orchestrated Response Execution
AWS provides a rich set of services for building an effective security posture. However, security teams must establish automated orchestration of these services. AWS Systems Manager integrates with EventBridge and Security Hub for event-driven automation. This enables it to execute runbooks and automation documents during security incidents. Therefore, it ensures consistent, repeatable response actions across AWS accounts and resources. Overall, security teams can use AWS Systems Manager to support rapid, controlled remediation without requiring manual intervention.
Guide to Best Practices for AWS Security Incident Response
AWS Services provide many capabilities for AWS security incident response, highlighted by this guide. However, security teams must follow certain best practices to leverage their potential fully.
Build Automation into Every Response Step
Security teams’ ultimate goal is to ensure that automation is built into every response step. This is because manual responses increase latency and human error during incidents. The two AWS services that support automated responses are EventBridge and Lambda, which automate repetitive detection and remediation tasks. Also, integrate Systems Manager runbooks for orchestration and multi-account actions. However, it is still crucial to include human approval for high-impact remediation steps (e.g., resource termination).
Maintain Continuous Visibility and Logging
It is vital to have continuous visibility and logging to ensure there are no opportunities for attacks by malicious actors. The best way to achieve this is to centralize all CloudTrail and VPC Flow Logs across accounts through AWS Organizations. Also, set up automated feeding of logs into Security Hub for consolidated visibility and analytics. Additionally, security teams should establish retention policies that meet compliance and forensic requirements. Furthermore, teams must regularly validate that log delivery and monitoring configurations are active and unaltered.
Practice Regular Incident Simulations (“Game Days”)
Security teams should test their incident response systems by conducting simulated incidents to evaluate team readiness and automation effectiveness. These simulations should also include failure injection scenarios such as compromised IAM credentials or S3 exposure. They should assess critical results of these simulations, including detection time, containment speed, and recovery efficiency. They should then use these assessments to update playbooks and automation scripts.
Enforce Least Privilege and Access Hygiene
While security incident response is critical, prevention is better than cure, and enforcing least privilege and access hygiene is equally vital. Therefore, security administrators should apply IAM least privilege across all accounts, services, and roles. Additionally, both manual and automated processes should be in place to regularly rotate credentials and eliminate unused keys or roles. Security teams should also make use of IAM Access Analyzer to identify and remediate excessive permissions. Also, they should enforce multi-factor authentication (MFA) as an additional security layer, especially for all privileged and administrative access.
Align with AWS Well-Architected Security Pillar
Experienced experts have built the AWS Well-Architecture framework based on best practices in the IT industry, including security. Therefore, security teams should use this to assess their security posture maturity. They should also map their incident response processes to Security Pillar best practices. The AWS services Trusted Advisor and Config also provide continuous compliance testing based on this framework for automated incident response implementations. Finally, teams also always treat each incident response as an evolving process that improves with every event.
Conclusion: Strengthening AWS Security Incident Response with Confidence
Reinforcing the Value of a Structured AWS Security Incident Response Guide
This guide has taken a holistic approach to AWS security incident response by emphasizing preparation, automation, and continuous learning. Additionally, it has surveyed core AWS services that facilitate automated responses to AWS security events and their orchestration. These services include GuardDuty, CloudTrail, Security Hub, and EventBridge, which work together for detection, containment, and recovery. Also, when security teams follow a structured approach, they will minimize downtime, limit damage, and ensure compliance with regulatory frameworks. Therefore, this guide’s purpose is to help teams protect AWS environments with confidence and operational resilience.
Evolving with the Cloud Security Landscape
Because threats are continually evolving, security teams must constantly update their security response postures due to the changing threat landscape. Therefore, this guide encourages teams to perform ongoing testing, automation refinement, and post-incident analysis to maintain readiness. Teams must understand that effective AWS security incident response is not a one-time exercise due to the changing nature of the cybersecurity landscape. They need to proactively cultivate the discipline of strengthening trust and resilience in every cloud operation. This AWS security incident response guide helps teams embark on the journey of always being one step ahead of cybersecurity threats.
Further Reading
AWS Security Incident Response Technical Guide
AWS Security Cookbook: Practical solutions for managing security policies, monitoring, auditing, and compliance with AWS
by Heartin Kanikathottu
Incident Response: A Strategic Guide to Handling System and Network Security Breaches
by E. Eugene Schultz, Russell Shumway
Incident Response & Computer Forensics, Third Edition 3rd Edition
by Jason T. Luttgens, Matthew Pepe, Kevin Mandia
AWS Penetration Testing: Beginner’s guide to hacking AWS with tools such as Kali Linux, Metasploit, and Nmap
by Jonathan Helmus
Cloud Security: A Comprehensive Guide to Secure Cloud Computing, 1st Edition
by Ronald L. Krutz and Russell Dean Vines
Security Chaos Engineering: Sustaining Resilience in Software and Systems, 1st Edition
by Kelly Shortridge
The Cybersecurity Playbook: How Every Leader and Employee Can Contribute to a Culture of Security, 1st Edition
by Allison Cerra
Affiliate Disclosure: As an Amazon Associate, I earn from qualifying purchases. This means that if you click on one of the Amazon links and make a purchase, I may receive a small commission at no additional cost to you. This helps support the site and allows me to continue creating valuable content.