
Introduction to Handling Large Datasets in AWS
Many AWS-based data handling and ML applications working with big data must leverage handling large datasets in AWS. Increasing digitization has led to numerous sources generating massive volumes of data, which are overwhelming traditional data processing systems. Moreover, the rate of data generation is rarely constant but fluctuates with peak volume only at certain times. Therefore, systems have the capacity to handle data volume at peak times, but they often remain underutilized during off-peak times. Many systems have regulatory compliance for long-term data retention and must manage ever-expanding datasets.
Many data-handling applications, including real-time analytics, machine learning, and IoT, depend on large datasets to make meaningful inferences.
Since data volume fluctuates, having a scalable system will improve resource utilization. Handling large datasets in AWS provides several services that scale on demand to meet changing data volumes. Some more common examples include S3, EMR, and Redshift. These fully managed services eliminate the need to provision resources manually. They also seamlessly integrate many AWS machine learning, analytics, and automation tools. Therefore, AWS is a powerful ecosystem for scalable data processing.
Key Challenges with Large Datasets
In The Power of Big Data, we considered handling large datasets in AWS characterized by volume, velocity, and variety. Data volume has risen exponentially with digitization pervading all aspects of life, making enormous storage demands on data processors. Not only has data volume has risen, but the rate of creation is also rising exponentially. Information processing often had to process higher data rates in real time, straining computational resources. In the past, information processors only had uniformly structured data to store and process. However, now they handle data from multiple sources with their own data structures or even unstructured data.
Handling large datasets in AWS can cause bottlenecks within data ingestion pipelines by overwhelming network bandwidth and slowing down ingestion speed. When ingestion pipelines are not optimized, they will struggle to keep up with incoming data. This is exasperated when complex formats demand increased parsing and transformation, further slowing down ingestion.
Further considerations are around balancing performance needs around storage costs. There are storage solutions that provide high-speed access to large volumes of data but are very expensive. Designers must scope current and future storage and transfer rate needs to arrive at the most economical solution.
Handling large datasets in AWS also magnifies the engineering challenges in protecting their contents to meet regulatory requirements for security and privacy.
AWS Services for Handling Large Datasets

Amazon S3
Amazon S3 is the storage workhorse for handling large datasets in AWS, given its scalable storage and lifecycle policies. Its standard scalable storage has data access speeds suitable for the majority of applications, offering good value for money. S3 also provides cheaper long-term storage options with price being inverse to access times, enabling cost savings. Life-cycle policies support this where data is transitioned to less expensive storage when consumers no longer need its high availability.
Amazon Athena supports S3 with handling large datasets in AWS by providing data querying to files stored in S3. This eliminates the expense of using databases to make data queryable, providing a cost-effective solution.
Amazon S3 is highly useful, but its data access speed is inadequate for many applications. Engineers can use Data Pipeline to mitigate this through data workflow orchestration, matching S3 to consumers requiring faster data rates. Data Pipeline can either pre-stage, transform, or move data to faster services like EMR or Redshift.
Amazon Redshift
However, there are many use cases where faster query times are needed, which Amazon S3 coupled with Athena cannot deliver. Amazon Redshift supports a more efficient handling of large datasets in AWS through columnar table structures, allowing optimized querying. This also allows far more complex queries and low-latency analytics over large datasets when this is critical. It is also far more ideal when integrating with BI tools like Tableau or Quicksight.
AWS EMR
Processing is the other part of handling large datasets in AWS. Amazon EMR enables this processing with either Hadoop or Spark frameworks. Both these frameworks enable distributed processing, allowing multiple workers to process large datasets. They allow clusters of processors to scale to match the current workload and allow spot instances for task nodes. The latter case allows for the realization of savings.
AWS Glue
AWS Glue is a better choice for less intensive handling of large datasets in AWS. It offers the advantages of Spark framework processing but with a serverless offering, reducing both cost and management overhead. It is highly suited for ETL and offers many out-of-the-box components, and users can visually design the ETL workflows. For a detailed guide on preparing and transforming data for ML workflows, see our article on AWS ML data preprocessing.
Amazon Kinesis
Collating data from one or many sources is another part of handling large datasets in AWS. Amazon Kinesis provides data streaming that seamlessly integrates with other AWS services, completing the large dataset processing workflow.
Best Practices for Handling Large Datasets in AWS
Amazon provides several powerful services for handling large datasets in AWS, leveraging distributed processing and memory. However, these alone will not guarantee efficient data management, and we must follow best practices to harness their full power.
Data Partitioning and Compression
Data partitioning is a valuable best practice since it allows engineers to improve efficient data handling by leveraging distributed processing. Multiple computer nodes are able to perform parallel processing and speed up data processing throughput. It can also reduce query scans where data reads are limited to the relevant subsets.
Another key practice for handling large datasets in AWS is data compression, which minimizes the physical size of datasets. This reduces storage costs while speeding up inter network data transfer with reduced payload size. Processing efficiency is also improved through reduced I/O operations.
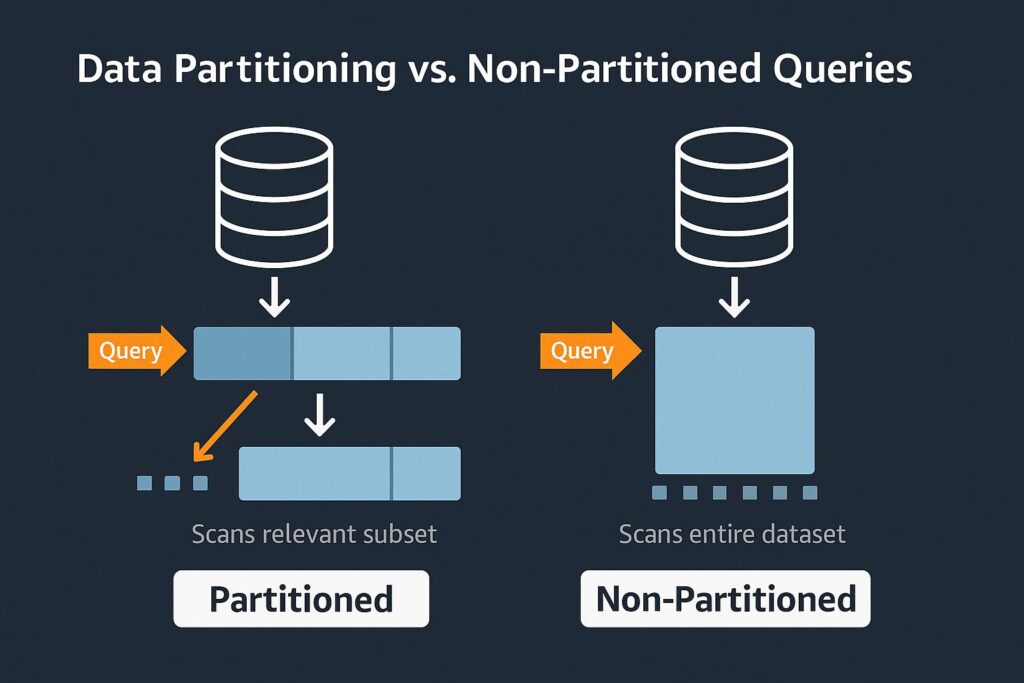
Correct File Format Selection
Storing data in a format that is compatible with the AWS data processor yields further efficiencies in data management. Also, optimized file formats reduce storage size and improve query performance. Columnar formats like Parquet and ORC allow analytics to read only the columns they need to improve processing speed. Other formats that are splittable enable parallel processing that improves data throughput. Avro is another useful format that includes schema metadata that simplifies data integration.
Workflow Automation for Handling Large Datasets in AWS
AWS Step Functions, complemented with Lambda Functions, allows engineers to simply and easily automate handling large datasets in AWS. They reduce manual errors and ensure consistency in data management workflows. Also, they save time and resources by streamlining repetitive operations like ETL, backups, and data archiving.
Secure Handling
While our focus is on efficiency and cost optimization for managing large datasets, we cannot ignore security considerations. Encryption protects data should unauthorized entities gain access when it is either in storage or transmission. However, IAM provides authentication and authorization to prevent unauthorized users from gaining access.
Cost Optimization Strategies for Handling Large Datasets in AWS

All projects operate with finite resources and need good cost optimization when handling large datasets in AWS.
S3 offers a very competitive price for storage but offers several other options to further save on costs. These options cater to long-term storage where organizations do not need as frequent access. However, in some cases, it is not easy to plan in advance, or manually checking data use frequency is highly cumbersome. S3 Intelligent-Tiering deploys algorithms based on data access frequency to shift it between storage options. Organizations can take advantage of opportunities to save on costs.
EMR is widely used for handling large datasets in AWS, but EC2 instance clusters are expensive with high-end computation. Spot instances are an opportunity to use excess capacity in the cloud environment at savings up to ninety percent. The only catch is that the EMR job must give them up within two minutes when other jobs bid more for these instances. However, making processes robust to losing processing instances overcomes this, and they can realize substantial cost savings.
At the other extreme are Redshift instances also handing large datasets in AWS, where the work is predictable. Since there is little variability over months or years, then reserved instances are a good cost-saving option. Here, organizations pay in advance for several years ahead, that are less costly than running EC2 instances on-demand.
Taking advantage of these different options will yield cost savings. However, it is still up to the operators to plan, monitor, and adjust continuously to ensure optimal cost savings. AWS Cost Explorer allows engineers to arrive at the optimal mix of services that will optimize cost. AWS CloudWatch allows engineers to perform ongoing monitoring of services where cost patterns may change over time.
Real-World Use Case: Financial Data Processing
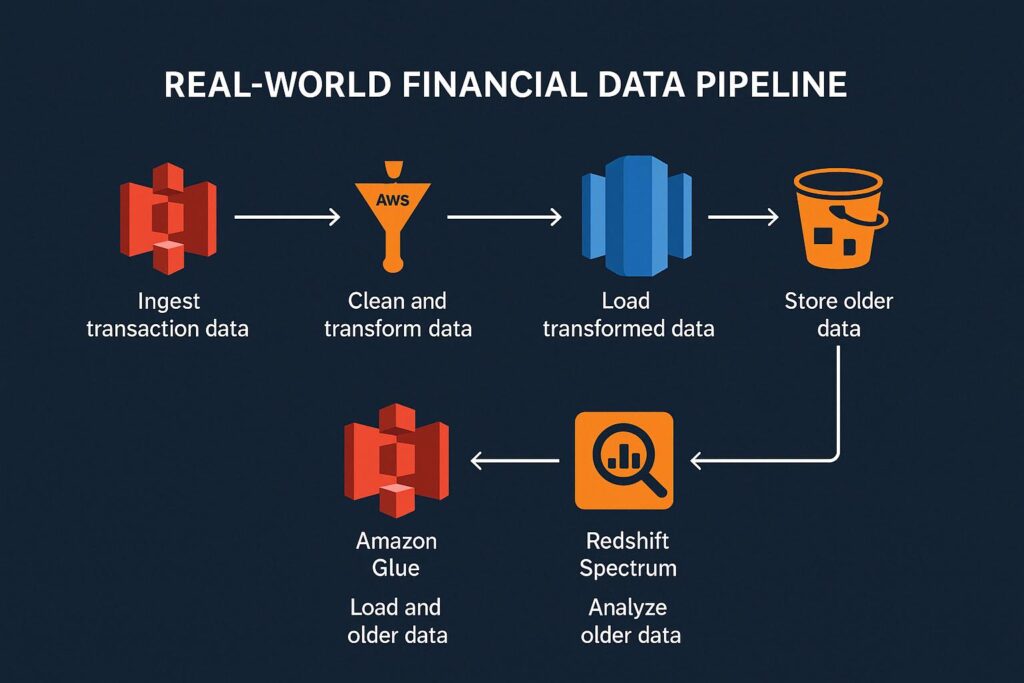
Financial firms are prime candidates for applying handling large datasets in AWS. They need to handle large transaction volumes from their multiple branches. The crucial first step is to ingest this data daily into centralized storage. AWS S3 has a good price per storage to serve as a data lake for this transactional data.
Financial firms will then need to clean this data and transform it so that analytical services can derive meaningful information. They can utilize AWS Glue to clean, transform, and catalog this data, making it ready for analysis.
Financial firms often require high-speed querying and reporting of this data. Data warehouse solutions like Redshift provide this ability. Financials firms can implement a pipeline once AWS Glue has performed ETL; the data is then uploaded to Redshift.
Redshift also allows the running of complex queries on their data that can detect trends, anomalies, and compliance risk. With older data that is accessed less frequently, engineers can move this to S3 and utilize Redshift Spectrum for analysis.
This pipeline can support a throughput of terrabytes of data with scalable performance at each stage. Also, all stages in this pipeline support secure access control, allowing full compliance with regulatory bodies.
Conclusion and Next Steps with Handling Large Datasets in AWS
AWS provides several key services that leverage AWS cloud infrastructure with distributed processing and memory. These are S3, Redshift, Amazon Glue, EMR, and Kinesis, where engineers can build pipelines for handling large datasets in AWS. These pipelines ingest and transform these large datasets, preparing them for analytical tools. Whilst building these pipelines, it is essential to follow best practices to take full advantage of these services. These include partitioning data, compressing data, properly formatting data, and setting up an automated pipeline. Finally, engineers should follow several cost optimization strategies, including using spot and reserved instances.
Further Reading
If you’re interested in exploring AWS data engineering further, these recommended books provide valuable insights:
- Amazon Web Services in Action, Third Edition – Michael Wittig & Andreas Wittig
A hands-on guide to AWS services with practical examples and updated coverage of cloud-native infrastructure. - Data Engineering with AWS: Learn how to design and build cloud-based data solutions – Gareth Eagar
Ideal for data engineers and architects building scalable data pipelines using AWS services. - Designing Data-Intensive Applications – Martin Kleppmann
A foundational book on modern data systems, covering data modeling, scalability, and fault tolerance.
Disclaimer: This section contains affiliate links. If you purchase through these links, we may earn a small commission at no additional cost to you. This helps support the site and keeps our content free.
References
- Amazon Web Services – Big Data on AWS
https://aws.amazon.com/big-data/ - AWS Glue Documentation
https://docs.aws.amazon.com/glue/ - Amazon S3 Storage Classes
https://aws.amazon.com/s3/storage-classes/ - Amazon Redshift Overview
https://aws.amazon.com/redshift/ - AWS Cost Optimization Best Practices
https://docs.aws.amazon.com/wellarchitected/latest/cost-optimization-pillar/