
Introduction: Unlocking TensorFlow’s Potential for Big Data
TensorFlow is an important tool for analyzing and processing big data, and its effects are revolutionary. Big data continues to evolve and impose ever-increasing demands on processing. Advanced TensorFlow for big data techniques addresses these demands. In this article, we explore these cutting-edge techniques that address challenges around processing big data. These range from transfer learning to real-time data analysis that empowers developers. We will dive into these advanced practices that optimize TensorFlow for scalable, high-performance big data applications.
Section 1: The Role of Transfer Learning in Advanced TensorFlow for Big Data
1.1 What Is Transfer Learning?
Long iterative training times potentially limit the building of new models for real-world solutions. Each model has no knowledge, and it must be trained from scratch, which is also very expensive and time-consuming. However, reusing pre-train models and adapting them to new applications is possible, thereby saving time and resources. Therefore, organizations benefit from eliminating the need to train models from scratch. This technique is commonly applied to image and text processing tasks. TensorFlow provides a suite of pre-trained models for rapid model deployment. The basic transfer learning sequence is illustrated below.
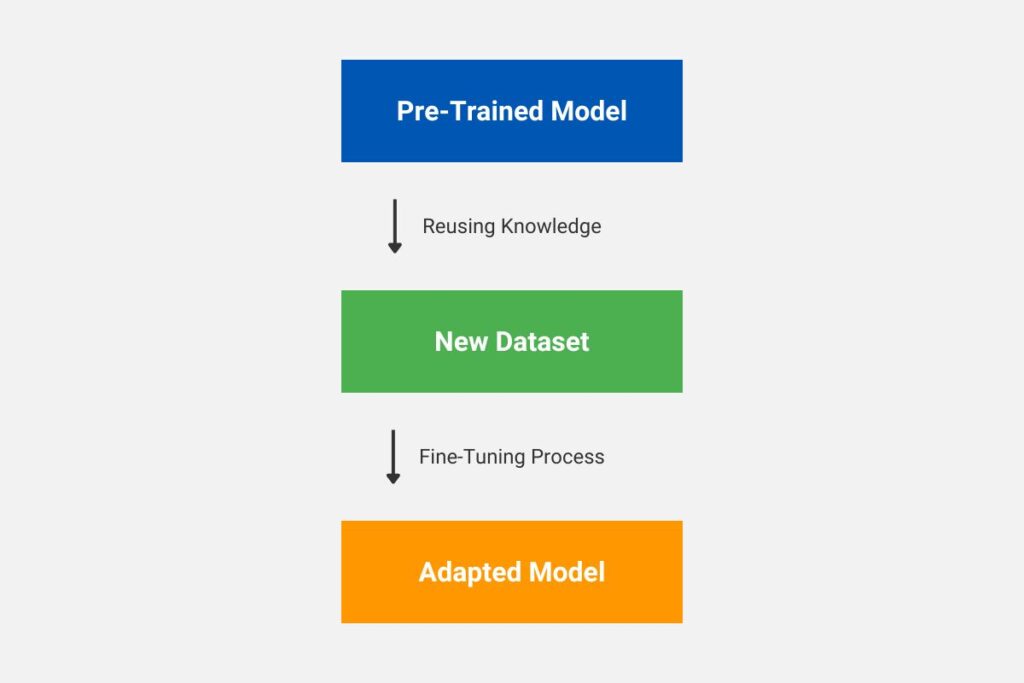
1.2 Benefits of Transfer Learning
Given its ever-increasing size and volume, transfer learning is becoming essential for handling big data. Transfer learning accelerates model training on vast datasets, reducing computational demands, costs, and learning time. This allows for leveraging state-of-the-art research and enhancing model accuracy with minimal data.
1.3 Exploring Pre-Trained Models for Advanced TensorFlow Techniques for Big Data Analysis
Pre-trained models are accessible through TensorFlow Hub and include InceptionNet, EfficientNet, MobileNet, and BERT. These models are crucial for optimizing TensorFlow for big data projects and accelerating deployment across industries. EfficientNet is designed for scalable image classification, offering high accuracy but reducing computational requirements. MobileNet is applicable for mobile and edge devices, providing lightweight and efficient real-time image and video analysis solutions. BERT is a pre-trained natural language processing model quickly adapted to new use cases. Companies can unlock versatility through customizing these pre-trained models. The image below provides a visual overview of these popular pre-trained models and their key applications.
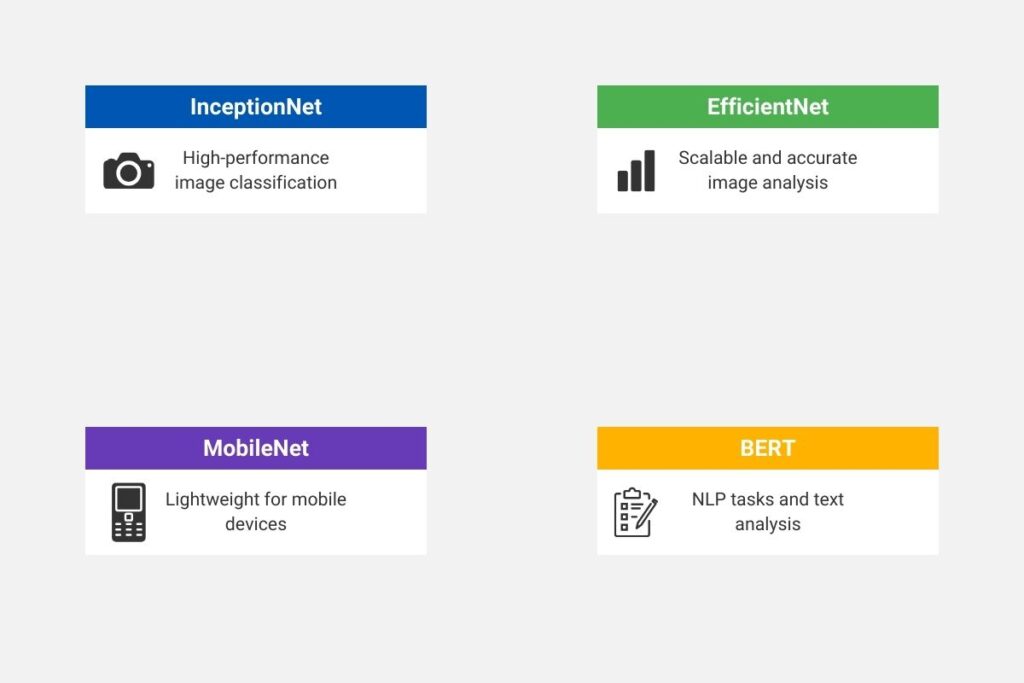
1.4 Implementing Transfer Learning for Real-Time Big Data Solutions with TensorFlow
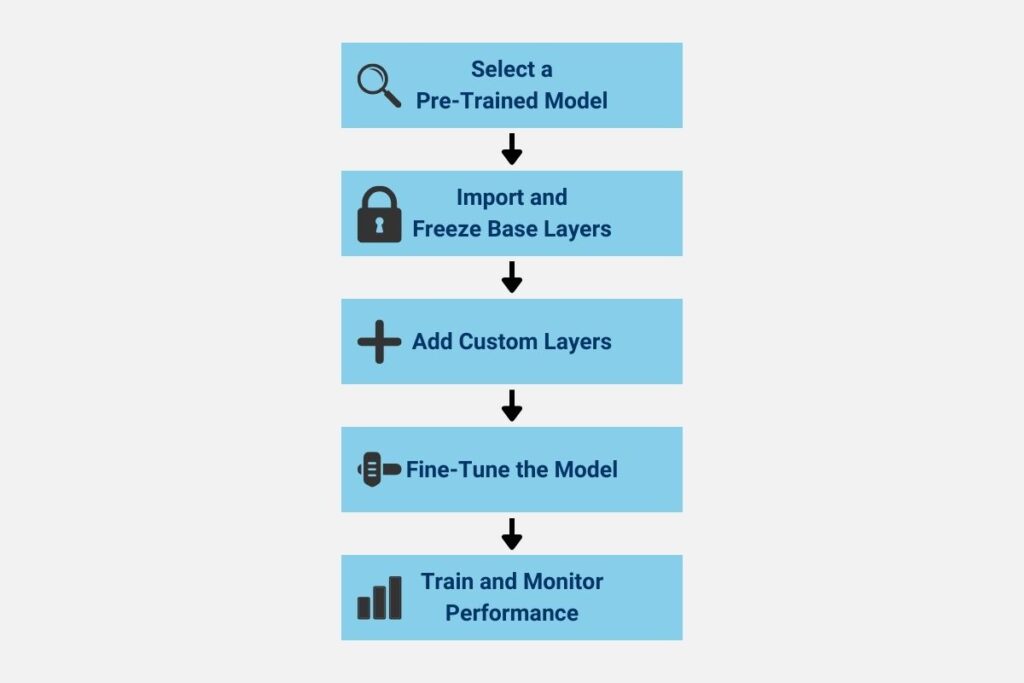
It is necessary to follow several steps in order to implement transfer learning successfully. The first step is correctly identifying a pre-trained model that best applies to your use case, especially when implementing real-time big data solutions with TensorFlow. Next, import that model into your project using TensorFlow’s tf.keras or TensorFlow hub. Freeze the base layers to preserve pre-trained knowledge during the initial training. Add and configure any new layers tailored to your dataset and application. Finally, train and fine-tune the model using your dataset, monitoring performance iteratively. When fine-tuning, three common approaches include Layer Freezing, Learning Rate Adjustment, and Gradual Unfreezing. The following diagram provides a visual representation of the steps involved in implementing transfer learning.
import tensorflow as tf
import tensorflow_hub as hub
from tensorflow.keras import layers, models
# Step 1: Select a Pre-Trained Model
model_url = "https://tfhub.dev/google/imagenet/inception_v3/classification/5"
pretrained_model = hub.KerasLayer(model_url, input_shape=(224, 224, 3), trainable=False)
# Step 2: Freeze Base Layers
base_model = models.Sequential([pretrained_model])
# Step 3: Add Custom Layers
base_model.add(layers.Flatten())
base_model.add(layers.Dense(128, activation='relu'))
base_model.add(layers.Dropout(0.5))
base_model.add(layers.Dense(10, activation='softmax')) # Output layer for 10 classes
# Step 4: Fine-Tune the Model
for layer in base_model.layers[:1]: # Adjust first layer as needed
layer.trainable = True
# Step 5: Compile and Train
base_model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Load your dataset here
# (x_train, y_train), (x_test, y_test) = your_dataset()
# Train the model
# base_model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=10)
print("Transfer learning model is ready for training!")
1.5 Best Practices for Transfer Learning
Transfer Learning, when correctly applied, will dramatically improve the training process. In addition to the steps outlined above, there are several considerations for best practices. You should augment your training data to improve your model’s robustness and generalization. Normalizing the training data to match the format and size of the pre-trained model is also essential. Another consideration is overfitting and model stability; dropout layers go a long way to address these issues. It is also vital to effectively fine-tune hyperparameters, making it necessary to evaluate loss and accuracy regularly. TensorFlow provides a suite of learning tools, including TensorFlow Hub, that help streamline implementation.
Section 2: Custom Layers and Functions for Advanced TensorFlow in Big Data Processing
In addition to Transfer learning, TensorFlow allows developers to customize their models, making it an exceedingly versatile framework. This section explores several TensorFlow customization capabilities.
2.1 2.1 Enhancing Big Data Models with Custom Layers in Advanced TensorFlow for Big Data Analysis
Many neural architectures often rely on specific layers oriented to particular tasks. Subsequently, TensorFlow allows developers to create layers tailored to specific tasks, yielding several benefits. Developers can enhance model adaptability to unique data types through layers designed to process these data types. Furthermore, custom layers can improve accuracy with domain-specific features. Image processing for self-driving is a good example. Developers can also streamline implementation by leveraging TensorFlow’s built-in functions and APIs to define custom layers. Another benefit is that developers can boost model performance through customization. The following diagram illustrates data flow through a custom layer in a TensorFlow model.
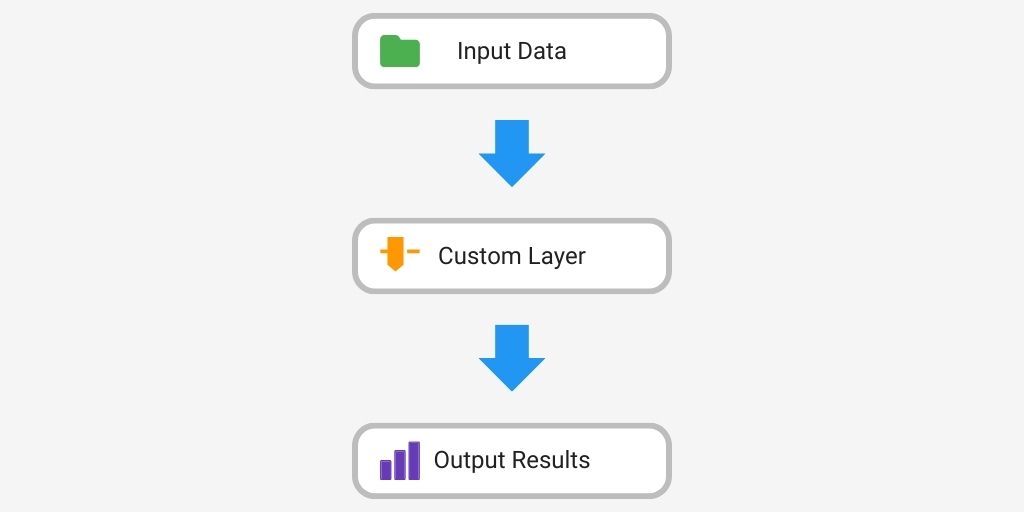
The following code example demonstrates how to create and use a custom layer in TensorFlow, as illustrated in the previous diagram.
import tensorflow as tf
# Step 1: Define a Custom Layer
class CustomDenseLayer(tf.keras.layers.Layer):
def __init__(self, units=32, activation=None):
super(CustomDenseLayer, self).__init__()
self.units = units
self.activation = tf.keras.activations.get(activation)
def build(self, input_shape):
# Initialize weights and biases
self.w = self.add_weight(
shape=(input_shape[-1], self.units),
initializer="random_normal",
trainable=True,
name="weights"
)
self.b = self.add_weight(
shape=(self.units,),
initializer="zeros",
trainable=True,
name="biases"
)
def call(self, inputs):
# Apply linear transformation and activation
output = tf.matmul(inputs, self.w) + self.b
return self.activation(output) if self.activation else output
# Step 2: Use the Custom Layer in a Model
inputs = tf.keras.Input(shape=(10,))
x = CustomDenseLayer(units=64, activation='relu')(inputs) # Apply custom layer
x = tf.keras.layers.Dense(32, activation='relu')(x) # Standard Dense Layer
outputs = tf.keras.layers.Dense(1, activation='sigmoid')(x) # Output layer
# Step 3: Compile and Train the Model
model = tf.keras.Model(inputs, outputs)
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Step 4: Dummy Data for Training
import numpy as np
X_train = np.random.random((1000, 10))
y_train = np.random.randint(0, 2, size=(1000, 1))
# Train the model
model.fit(X_train, y_train, epochs=5, batch_size=32)
# Step 5: Summary of the Model
model.summary()
2.2 Using Function Decorators for Optimization
Function decorators are a powerful tool in Python that allows you to modify the behavior of a function without changing its core logic. In TensorFlow, decorators can optimize performance, add logging, or enforce constraints. This allows developers to optimize custom layers using TensorFlow decorators. This further simplifies complex operation creation by encapsulating repetitive logic and automating optimizations. Therefore, developers can enhance runtime efficiency with these optimized functions through their decorators. Developers can also use decorators to manage computational workflows. Another vital feature of decorators is allowing components to integrate seamlessly into TensorFlow models. They achieve this by simplifying and standardizing how functions and custom operations are used and defined. The diagram below visually represents how a decorator modifies a custom function in TensorFlow.
The following code example demonstrates how to define and apply a decorator to a TensorFlow function, as visualized in the preceding diagram.
The following code example demonstrates how to define and apply a decorator to a TensorFlow function, as visualized in the preceding diagram.
import tensorflow as tf
import time
# Step 1: Define a Decorator for Function Timing
def timing_decorator(func):
def wrapper(*args, **kwargs):
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
print(f"Function '{func.__name__}' executed in {end_time - start_time:.4f} seconds")
return result
return wrapper
# Step 2: Use the Decorator to Optimize a TensorFlow Function
@timing_decorator
def compute_tensor_operations(x):
# Simulated TensorFlow operations
x = tf.constant(x, dtype=tf.float32)
x = tf.square(x)
x = tf.sqrt(x)
x = tf.reduce_sum(x)
return x.numpy()
# Step 3: Run the Function with the Decorator Applied
input_data = [i for i in range(1, 100001)] # Large input for demonstration
result = compute_tensor_operations(input_data)
# Output the Result
print(f"Result of Tensor Operations: {result}")
2.3 Flexibility in Model Design
The overall goal of custom layers and functions is to provide flexibility when designing models. Developers are painfully aware of the need to adapt model architectures for the often present unstructured data. Since the real world is messy, developers must tailor model outputs and define custom activation functions. Input data is often disorganized, and developers must integrate advanced algorithms into layers to handle poor data. Another consideration is that different use cases have unique features associated with those use cases. Therefore, developers must customize feature extraction with specialized methods depending on the use case. Also, these design strategies should be modular, allowing developers to assemble models quickly and easily. The diagram below illustrates how custom layers can handle unstructured data and produce structured output.
2.4 How to Create Custom Layers in TensorFlow
Having considered custom layer benefits and their uses, we have arrived at a description of how to create them. TensorFlow provides the ability to create custom layers through the tf.keras.layers.Layer class. The developer overrides essential methods in this class, including call and build. The developer also needs to define parameters and initializations specific to their tasks. Next, it is crucial that the developer tests and debugs example datasets to verify functionality. Also essential is that the developer documents the layer’s purpose and usage so that other developers can utilize it efficiently.
2.5 Testing and Debugging Custom Layers in Advanced TensorFlow for Big Data
As part of implementing a custom layer, we mentioned that a critical stage is testing and debugging. We will now further elaborate on that stage. A critical software engineering activity is performing extensive unit tests. This is also extended to validating custom layers, and developers must never omit this stage. Following unit test validation, developers must check that model output shapes align with expectations. Developers can use TensorFlow’s debugging tool to troubleshoot whenever errors or poor test results are encountered. Developers should also build diverse datasets to test layer performance in various scenarios. This allows developers to refine layers based on test results iteratively. The following diagram illustrates the key stages in testing and debugging custom layers in TensorFlow.
Section 3: Scaling TensorFlow Models with Distributed Computing
3.1 Introduction to Distributed Training
Big data results in large datasets applied to training algorithms, creating a significant demand for computing resources. This makes it impractical for a single processor to complete tasks in a reasonable time, so training must be distributed across multiple devices by splitting tasks. The diagram below illustrates how a dataset can be distributed across multiple GPUs for parallel processing.
Meeting these high computational demands requires specialized hardware, including GPUs, TPUs, or clusters. Distributed computing is vital for managing massive bid data workloads. Therefore, TensorFlow includes the tf.distribute API that simplifies distribution without developers needing to hand code computational distribution. This API enhances model efficiency and scalability. The following code example demonstrates how to use the tf.distribute.MirroredStrategy to distribute training across multiple GPUs.
import tensorflow as tf
# Create a MirroredStrategy for multi-GPU training
strategy = tf.distribute.MirroredStrategy()
print('Number of devices: {}'.format(strategy.num_replicas_in_sync))
# Define a model within the strategy scope
with strategy.scope():
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=(128,)),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Dummy data for demonstration
import numpy as np
x_train = np.random.random((1024, 128))
y_train = np.random.randint(10, size=(1024,))
# Train the model
model.fit(x_train, y_train, epochs=10, batch_size=32)
3.2 Strategies for Distributed Training and Real-Time Big Data Solutions with TensorFlow
Different distributed computing strategies are geared toward various situations. Therefore, it is a good practice to select the strategy that best fits the computing architecture. TensorFlow provides several strategies that adapt to varying workloads, including mirrored, multi-worker, and parameter server strategies. The diagram below illustrates these three distribution strategies and how they differ in their approach to distributed computation.
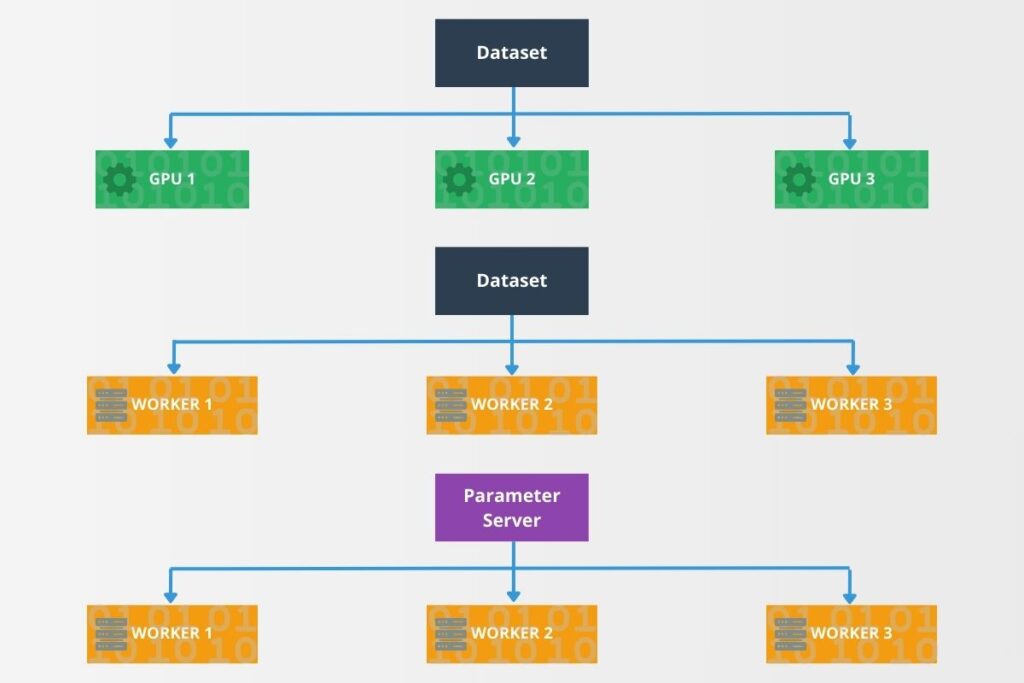
A mirrored strategy synchronizes training across multiple GPUs. A multi-worker strategy splits training across machines. A parameter server strategy manages shared model parameters. Each of these approaches ensures improved scalability and speed.
3.3 Setting Up TensorFlow Clusters for Advanced TensorFlow in Big Data Applications
Although TensorFlow provides tools for abstracting distributed computing, the developer must still apply sound design principles when setting up clusters. There are several stages in setting up TensorFlow clusters. The developer must define worker nodes and parameter servers in the cluster. The diagram below illustrates a typical TensorFlow cluster setup with a master node, worker nodes, and parameter servers.
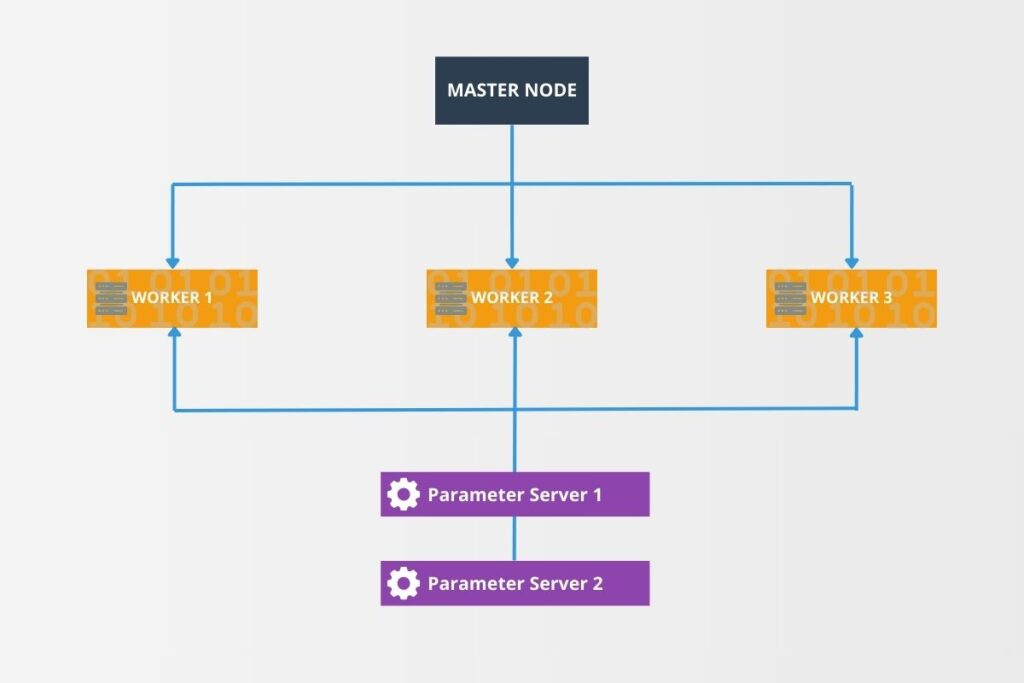
To achieve seamless operation, they must configure cluster specifications. The following code example demonstrates how to configure a TensorFlow cluster using TF_CONFIG, as illustrated in the preceding diagram.
import os
import tensorflow as tf
# Define TF_CONFIG environment variable
os.environ['TF_CONFIG'] = '''
{
"cluster": {
"worker": ["worker0.example.com:2222", "worker1.example.com:2222"],
"ps": ["ps0.example.com:2222"]
},
"task": {"type": "worker", "index": 0}
}
'''
# Verify the TF_CONFIG setup
print("TF_CONFIG:", os.environ['TF_CONFIG'])
# Example of starting a distributed strategy using TF_CONFIG
strategy = tf.distribute.experimental.ParameterServerStrategy()
with strategy.scope():
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation='relu', input_shape=(128,)),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
print("Cluster configured successfully.")
Communication between devices is critical, and developers must use TensorFlow tools to establish these communications. Testing the cluster setup before running any large training jobs is vital. Therefore, developers should apply small training tasks to test any cluster setup. Along with testing, developers must optimize cluster performance for efficiency.
3.4 Benefits of Distributed Training in Advanced TensorFlow for Big Data
We consider the challenges that big data brings to model training, and now we will describe the benefits that distributed computing brings. Distributed training reduces overall training time for models when vast training datasets are applied. Increasing recognition velocity with these models makes them more suited for a wide range of real-time applications. Real-time applications are increasingly becoming more coming with demanding consumers. Distributed training also improves accuracy when using larger datasets. There is also flexible scaling for meeting growing data needs. Another benefit is greater enhanced resource utilization across devices.
3.5 Common Challenges in Distributed Computing
Distributed computing provides many benefits that address big data challenges. However, the developer must perform tradeoffs against challenges introduced by distributed computing. Ironically, distributed computing can slow down training with synchronization overhead, which the developer needs to address. Along with distributed hardware, network latency impedes inter-device communication. Additional operation complexity is introduced with the need to manage cluster failures. Another key consideration is workload balancing, where imbalanced workloads potentially impact efficiency. The following diagram summarizes these common challenges and their corresponding solutions in TensorFlow.
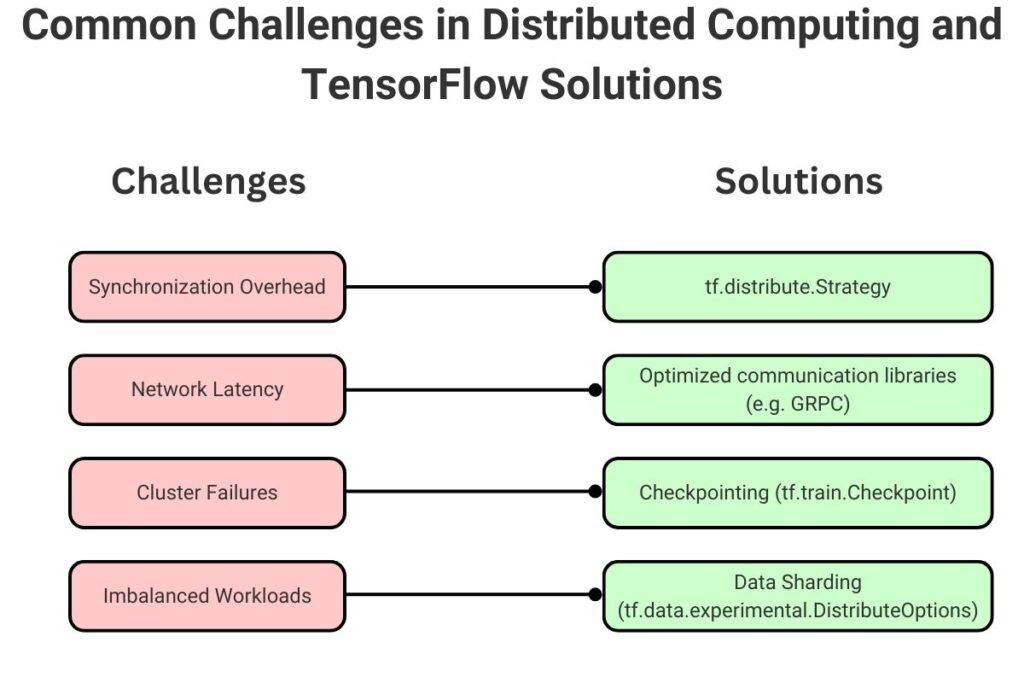
Fortunately, TensorFlow provides several tools developers can use to mitigate these challenges effectively.
Section 4: Optimizing TensorFlow Models for Performance
Often, training and deploying models occur on vast computing resources. However, many scenarios deploy models to devices with relatively limited computing resources. An example is deploying models to edge devices, often physically located at their point of use. The section considers how to adapt models to relatively limited computational resources.
4.1 Importance of Model Optimization for TensorFlow Big Data Projects
Optimizing TensorFlow for big data projects ensures efficient performance whenever training or deploying models to edge devices. These optimized models have reduced training and inference time for large datasets, which assists with lowering edge-device hardware requirements. Reduced inference time also significantly improves the overall user experience. Well-optimized models are also essential for scalable applications.
4.2 Techniques for Model Quantization
We have considered the need for model optimization and will focus on some techniques for optimizing models. Converting models to lower-precision formats like int8 is one essential optimization technique. This technique is weight quantization, which reduces memory and storage requirements. However, it is necessary to perform careful calibration to preserve model accuracy. TensorFlow provides tools that simplify the quantization process. Quantization enables better performance on limited hardware. The following diagram illustrates the process of model quantization.
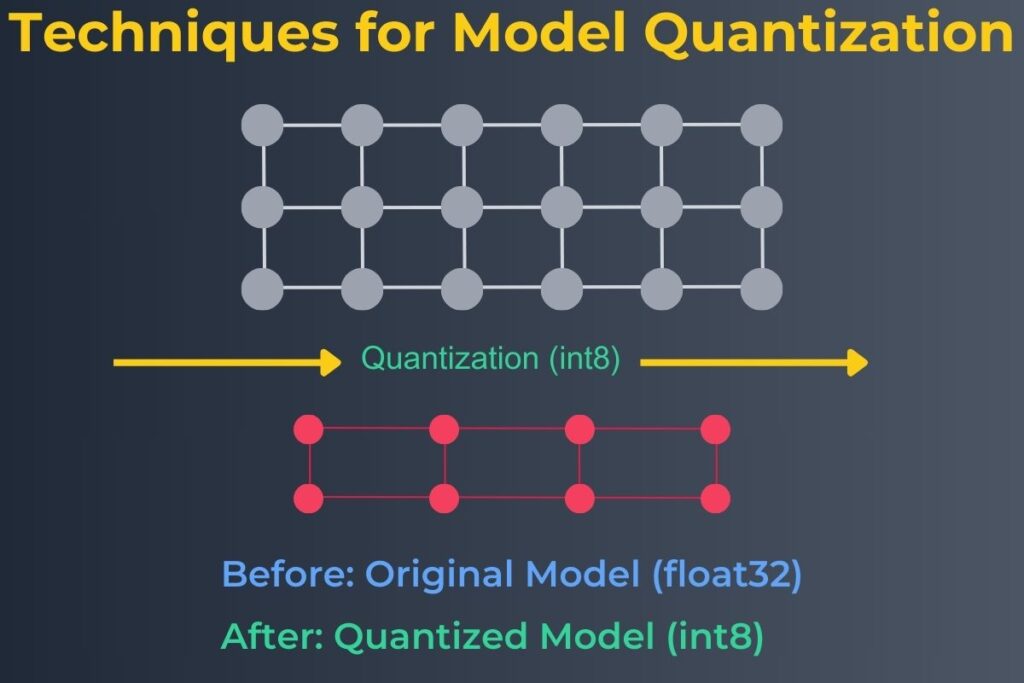
The following code example demonstrates quantizing a TensorFlow model using TensorFlow Lite, as illustrated in the preceding diagram.
import tensorflow as tf
# Load the trained model
model = tf.keras.models.load_model('model_path')
# Convert to TensorFlow Lite with quantization
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()
# Save the quantized model
with open('model_quantized.tflite', 'wb') as f:
f.write(tflite_model)
print("Model quantized and saved as model_quantized.tflite")
4.3 Implementing Pruning to Improve Efficiency
Pruning is another optimization technique that removes unnecessary weights to create streamlined models. They reduce complexity and subsequently improve model interpretability. Decreasing storage size is another benefit that allows more efficient deployment. TensorFlow also provides automated workflows that perform pruning operations. Pruning helps maintain accuracy while optimizing performance.
The following code example demonstrates how to apply pruning to a TensorFlow model using the tensorflow_model_optimization library.
import tensorflow_model_optimization as tfmot
import tensorflow as tf
# Load a simple model
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation='relu', input_shape=(100,)),
tf.keras.layers.Dense(10, activation='softmax')
])
# Apply pruning to the model
prune_low_magnitude = tfmot.sparsity.keras.prune_low_magnitude
pruning_params = {
'pruning_schedule': tfmot.sparsity.keras.PolynomialDecay(
initial_sparsity=0.2, final_sparsity=0.8, begin_step=0, end_step=1000
)
}
model_pruned = prune_low_magnitude(model, **pruning_params)
model_pruned.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
print("Pruned model created")
4.4 Deploying Models on Edge Devices
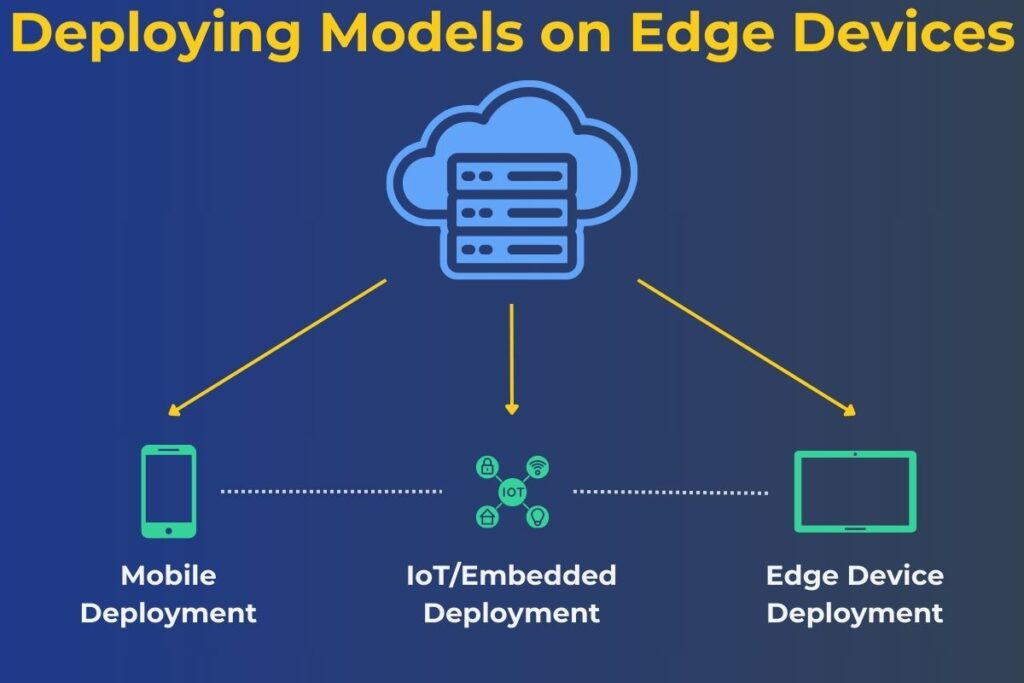
Several edge devices have different use cases, including mobile and IoT. Developers need to tailor models for these use cases. They can use TensorFlow Lite for these use cases, which enables lightweight and efficient deployment. This framework also lets developers test models in resource-constrained environments. It also allows developers to leverage hardware-specific optimization for better results. Another significant benefit of using this framework is that it ensures compatibility with a wide range of edge devices. The diagram below illustrates how TensorFlow models can be deployed on various edge devices.
4.5 Evaluating Optimized Models
Developers must also continually evaluate and improve these models to ensure optimal performance. They must compare metrics before and after optimization while testing models on diverse hardware configurations. Another important aspect of continuous improvement is analyzing real-world performance. Developers must also regularly update models to adapt to changing requirements while monitoring long-term efficiency and user satisfaction.
Conclusion: Elevating Big Data Solutions with TensorFlow
We have explored how advanced TensorFlow techniques unlock the potential of big data. Transfer learning and distributed training empower scalable applications, while optimization ensures that TensorFlow models perform efficiently in any environment. These real-time capabilities keep TensorFlow models ahead in handling dynamic datasets. Adopting these advanced techniques, including real-time big data solutions with TensorFlow, you can future-proof your projects for scalable growth.
Further Reading
We may earn a commission if you purchase through the links below at no extra cost to you. As an Amazon Associate, we earn from qualifying purchases.
Advanced Deep Learning with TensorFlow 2 and Keras, Rowel Atienza
Mastering TensorFlow 1.x: Advanced Machine Learning and Deep Learning Concepts, Armando Fandango
References
TensorFlow: Advanced Techniques Specialization.
How to integrate TensorFlow with big data platforms for processing and training on large datasets?
What is TensorFlow? Exploring Its Impact on Big Data and AI – AI Cloud Data Pulse
Exploring the Big Data Universe – AI Cloud Data Pulse