
1. Introduction
Optimizing neural networks will become the key differentiator in the age of deep learning. This is even with larger model sizes and increased processing speed, since these will hit diminishing returns.
There are several advantages to optimizing neural networks, including quicker training, which reduces training time and resource usage. They will also experience better performance during training, improving accuracy while reducing the number of training epochs needed. This improved performance is especially important when working with extremely large datasets. This compares favorably to poorly tuned models, where there is inefficient use of computational resources and cost increases.
It is important to select an appropriate framework for optimizing neural networks, and TensorFlow is one of the best candidates. TensorFlow is a leading open-source framework for building and training neural networks, which Google built and still actively supports. It is now extensively used by both research and industry with a proven track record. Most importantly, it provides powerful tools to facilitate optimization, scalability, and performance monitoring.
This guide will teach engineers practical TensorFlow techniques to optimize neural network models. It provides steps to improve accuracy and reduce training time while boosting model performance. Hence, engineers will have actionable tips to fine-tune their models for real-world AI applications.
For foundational concepts, see What is TensorFlow? Exploring Its Impact on Big Data and AI.
2. What Is Optimizing Neural Networks?
We need to define better what is meant by optimizing neural network models. In summary, this is how efficiently a model learns from data by reducing training time while maintaining or improving performance. It also looks to prevent overfitting by balancing model complexity against generalization. The other major goal is to improve inference speed and efficiency when operating in production environments.
We next want to explore the key goals around optimizing neural networks. Ultimately, we want to reduce the training steps needed, resulting in faster convergence. Another key goal is reducing loss, which demonstrates that the model’s prediction accuracy improves during training. The other side of the coin is that generalization is improving for performance on unseen data. Finally, we want better use of computational resources and reduced cost.
A key problem with any sort of optimization, including optimizing neural networks, is making tradeoffs. This includes faster training that can sometimes sacrifice model accuracy. On the other hand, higher performing models may need longer training and greater use of computational resources. Here, understanding the use case and non-functional requirements is critical to establishing the right balance between competing factors.
3. Using TensorFlow for Optimizing Neural Networks (400–450 words)
There are several approaches to optimizing neural networks that we will explore here. These include using out-of-the-box optimizers, tuning the learning rate, and performing regularization.
a. Optimizer Selection
TensorFlow provides several optimizers that machine learning engineers can apply to their neural networks. These include Adam, SGD, and RMSProp, which are suited for different use cases and non-functional requirements.
The Adaptive Moment Estimation (Adam) achieves quicker convergence by combining momentum and adaptive learning. It is most suitable when we want to perform minimal tuning, and Adam is readily usable. However, the tradeoff here is that these models may overfit or converge to suboptimal minima on certain training datasets. To use in TensorFlow, set optimizer = tf.keras.optimizers.Adam(learning_rate=0.001) for fast, adaptive convergence.
Using Stochastic Gradient Descent (SGD) for optimizing neural networks provides simplicity and stability for many deep learning problems. However, unlike Adam, it requires careful tuning of the learning rate, but it often benefits from momentum. Also, in contrast to Adam, its convergence is slower but has been generalized in some cases where Adam experiences overfitting. Therefore when you want stable momentum-drive updates then set optimizer = tf.keras.optimizers.SGD(learning_rate=0.01, momentum=0.9) in TensorFlow.
Root Mean Square Propagation (RMSProp) achieves neural network optimization by adapting learning rates per parameter. This makes it ideal for non-stationary objectives, and it performs well on RNNs and unstable gradients. However, it is less effective on use cases that need momentum or longer-term history. Therefore, for non-stationary objectives or noisy gradients, in TensorFlow, set optimizer = tf.keras.optimizers.RMSprop(learning_rate=0.001).

b. Learning Rate Tuning
Learning rate tuning is another key activity in optimizing neural networks, and understanding this is crucial for model training. What makes the learning rate central to training is that it controls the magnitude of the weights update following each step. Whenever we train a model with a high learning rate, the training may overshoot and diverge. However, when there is a low training rate, this can result in slower convergence. Another consequence is that the model gets stuck in local minima. Therefore, engineers should work on choosing a learning rate that balances speed with precision.
To assist with learning rate tuning, engineers can use learning rate schedulers that adjust the learning rate during training. These are semi-automated, where engineers specify the schedule logic to improve convergence. Learning rate schedulers also implement decay strategies that gradually reduce the learning rate to fine-tune the model as it learns.
The following diagram shows how an exponential decay schedule reduces the learning rate progressively over training epochs:

TensorFlow provides several built-in schedulers, including ExponentialDecay and ReduceLROnPlateau. The following Python code shows how to set up ExponentialDecay.
import tensorflow as tf<br><br>
# Define an exponential decay schedule<br>
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(<br>
initial_learning_rate=0.01,<br>
decay_steps=10000,<br>
decay_rate=0.9<br>
)<br><br>
# Apply the schedule to the optimizer<br>
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
c. Regularization Techniques
The other class of techniques central to optimizing neural networks is regularization techniques that help to prevent overfitting. Dropout is where training temporarily drops out randomly selected neurons or layers from the training model. These neurons or layers can provide pathways that cause the model to fit training data too closely, resulting in overfitting.
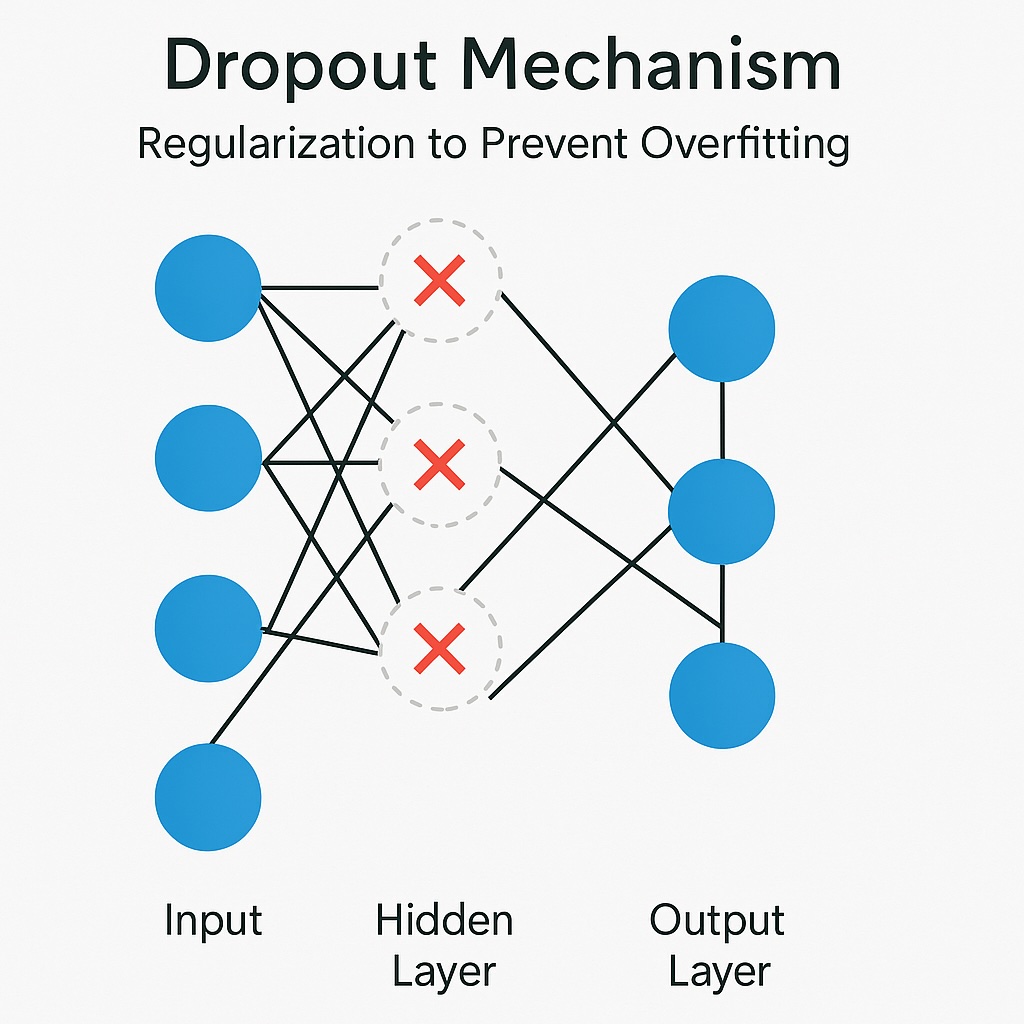
Whereas Dropout is concerned with neurons and layers, L1/L2 regularization deals with the weights in reducing model complexity. L1 regularization encourages sparsity by driving some weights to zero, while L2 regularization penalizes large weights. These keep the model simple and more generalizable and preventing overfitting to training data noise.
import tensorflow as tf<br><br>
# Build a simple model with Dropout and L2 regularization<br>
model = tf.keras.Sequential([<br>
tf.keras.layers.Dense(128, activation='relu',<br>
kernel_regularizer=tf.keras.regularizers.l2(0.001)),<br>
tf.keras.layers.Dropout(0.5),<br>
tf.keras.layers.Dense(10, activation='softmax')<br>
])
4. Neural Network Optimization in TensorFlow
Alongside optimizing neural networks, there are opportunities for improving training efficiency within TensorFlow. These include optimizing the data pipeline, using mixed precision, and making smart choices around batch size and hardware utilization.
a. Data Pipeline Optimization
Improving training efficiency for optimization neural networks is not only about the models themselves but also the supporting infrastructure. A vital infrastructure component is pipelines between the model and training data source, which are a potential source of bottlenecks. Improving these pipeline efficiencies will help to reduce these bottlenecks between data loading and model training. We can improve these efficiencies by making these pipelines scalable and operating in parallel. TensorFlow provides the tf.data API that enables scalable and parallelized pipelines.
Other optimization techniques include caching and prefetching. Caching keeps datasets in memory, allowing us to reuse across epochs and remove latencies around data transfer. Prefetching involves overlapping data preprocessing with model execution to boost transfer.
To prevent the model from memorizing data order, we can apply shuffling techniques.
b. Mixed Precision Training
Often, values that the model handles do not always require a high degree of precision, and often, lower precision suffices. Therefore, models can use both 16-bit and 32-bit floating-point types. This helps to speed up training and reduce memory usage without sacrificing model accuracy.
This is beneficial for GPU/TPU environments where mixed precision leverages specialized hardware like NVIDIA Tensor Cores for faster computation. It also reduces memory footprints on these processors, allowing for larger batch sizes. Mixed precision also helps to utilize the parallel processing capabilities of these modern accelerators fully.
TensorFlow provides the tf.keras.mixed_precision module to enable the benefits associated with mixed precision training.
c. Batch Size and Hardware Utilization
Batch size selection also contributes to optimizing neural networks. Here, larger batch sizes can improve training speed by enabling more efficient use of GPU or TPU parallelism. However, they require more memory, making them unsuitable for smaller devices. Another problem similar to large training rates is that they can easily end up in local minima with poorer generalization. Therefore, tuning becomes more critical.
Smaller batch sizes will result in longer convergence times, but use less memory, making them more suitable for limited-resource environments. They are also less likely to end up in local minima and have more stable convergence. Another benefit is better generalization due to more noise in gradient updates.
We can utilize batch size management through the tf.distribute.Strategy module provided by TensorFlow.
5. Monitoring for Optimizing Neural Networks
Optimizing neural networks is not a deterministic exercise and an iterative approach is often needed. This is applicable for both training and running these models as inference engines. Therefore, constant monitoring of model performance is necessary to ensure optimal performance continually.
TensorBoard is part of the TensorFlow framework that provides real-time feedback on model performance. It provides engineers with visual insights into model training metrics like loss and accuracy. Engineers can monitor training progress and observe overfitting when it happens. TensorBoard also provides real-time charts that allow engineers to fine-tune models using live performance data. Additional features include tracking learning rate changes, weight histograms, and activation distribution. It also supports profiling tools that allow engineers to analyze performance bottlenecks. Engineers also have the ability to compare multiple training runs for model tuning and integration with TensorFlow is available through callbacks.

There are several key metrics that provide valuable indications of model performance, including loss, accuracy, and overfitting signals. Loss is applicable to both linear and classification models, measuring the extent to which the model’s predictions are from actual values. Accuracy, which is usually applicable for classification models, indicates the percentage of correct predictions. Whenever loss is decreasing with stable accuracy, this indicates consistent learning.
Overfitting is crucial because it measures the gap between training and validation accuracy, indicating poor performance outside of training data. Another indicator of overfitting is spikes in validation loss while training loss drops.
The chart below illustrates how training and validation loss and accuracy evolve over epochs, highlighting typical patterns of overfitting:

Through tracking these metrics, engineers can guide both learning rates and regularization adjustments.
import tensorflow as tf<br><br>
# Set up TensorBoard callback<br>
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir="./logs")<br><br>
# Train the model with TensorBoard enabled<br>
model.fit(x_train, y_train,<br>
epochs=10,<br>
validation_data=(x_val, y_val),<br>
callbacks=[tensorboard_callback]<br>
)
7. Optimizing Neural Networks Summary
Optimizing Neural Networks consists of several strategies around the model and the infrastructure supporting the model. Optimization usually trades off between various conflicting goals, and selection depends on the particular use case and supporting infrastructure. Selecting the learning rate is the most common strategy, and TensorFlow provides optimizers for dynamically adjusting it. Regularization is another important optimization class that addresses whether models are too generalized or are overfitting their training data. Regularization either removes neurons or minimizes weights, depending on whether the model is overfitting or underfitting.
Infrastructure considerations also significantly contribute to model performance. Pipelines that transfer training data from its source to the model provide a significant opportunity for optimization. Value precision within the model can also help improve efficiency whenever lower precision is adequate. Batch size selection is another area that also contributes to optimizing neural networks.
Finally, it is essential to measure performance and adjust accordingly continually, and TensorBoard provides comprehensive monitoring of model performance.
Optimizing neural networks is an iterative activity, and it improves with gaining experience and experimentation. Therefore, it is crucial that engineers continually build their skills around this, and it is a major differentiator between engineers.
Further Reading
Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow (3rd Edition)
Author: Aurélien Géron
Deep Learning with Python (2nd Edition)
Author: François Chollet (creator of Keras)
TensorFlow for Deep Learning
Authors: Bharath Ramsundar & Reza Bosagh Zadeh
Deep Learning (Adaptive Computation and Machine Learning series)
Authors: Ian Goodfellow, Yoshua Bengio, and Aaron Courville
References
TensorFlow Documentation – Official guides and API docs for TensorFlow tools and techniques
https://www.tensorflow.org/
Keras Optimizers – Overview of available optimizers in tf.keras.optimizers
https://www.tensorflow.org/api_docs/python/tf/keras/optimizers
Learning Rate Schedules in TensorFlow
https://www.tensorflow.org/api_docs/python/tf/keras/optimizers/schedules
TensorBoard Visualization Tool – Monitor training, performance metrics, and profiling
https://www.tensorflow.org/tensorboard
Dropout: A Simple Way to Prevent Neural Networks from Overfitting – Srivastava et al. (2014)
https://jmlr.org/papers/volume15/srivastava14a/srivastava14a.pdf
CIFAR-10 Dataset – Canadian Institute for Advanced Research
https://www.cs.toronto.edu/~kriz/cifar.html
Mixed Precision Training Guide – TensorFlow’s official guide to tf.keras.mixed_precision
https://www.tensorflow.org/guide/mixed_precision
tf.data API – Efficient input pipelines for scalable training
https://www.tensorflow.org/guide/data
tf.distribute.Strategy – Distributed training support in TensorFlow
https://www.tensorflow.org/guide/distributed_training