
Introduction to AWS Incident Response
Organizations leveraging public clouds, such as AWS, must implement incident response best practices to minimize the impact of security breaches. They enable rapid containment and ensure prompt incident responses, minimizing the damage from security breaches. Importantly, they also ensure compliance with regulatory requirements in cloud environments. Therefore, implementing a strong plan will reduce downtime and business disruption while providing a structured response to investigating and remediating threats. Additionally, effective incident response safeguards sensitive data from unauthorized access. Also, it helps build resilience by preparing teams to handle evolving cloud threats. Conducting postmortems will build on lessons learned from incidents that will strengthen future security posture. These best practices contributed to a tested evolving response strategy that will increase customer and stakeholder trust.
Utilizing AWS GuardDuty is a typical incident response practice. An example is detecting whenever an IAM user’s access keys are being used from an unusual location. Subsequently, a strong incident response enables engineers to quarantine these credentials and investigate the source of compromise immediately. This prevents attackers from escalating access across the environment.
The AWS Security Specialty exam emphasizes incident response as a core domain. Thereby, testing engineers on their ability to detect, contain, and remediate security events in the cloud.
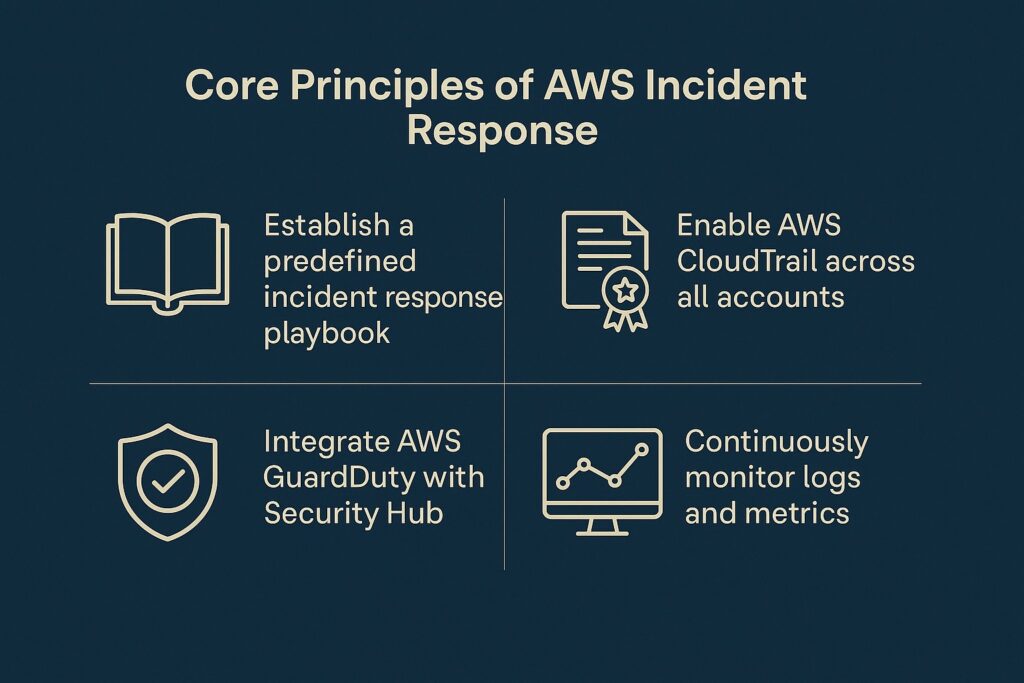
Core Principles of AWS Incident Response
The proverb ‘Well begun is half done’ resonates well with AWS incident response best practices regarding adequate preparation. Therefore, establishing a predefined incident response playbook will ensure that teams fully understand their roles before any incidents occur. Additionally, enabling AWS CloudTrail across all accounts will provide the audit trail needed for effective detection. Furthermore, integrating AWS GuardDuty with Security Hub will centralize threat intelligence for rapid analysis. Also, continuous monitoring of logs and metrics for early detection of unusual activity complements these best practices. Ultimately, security teams should conduct regular simulations and tabletop exercises to enhance their readiness for real-world attacks.
Along with security teams, automation and orchestration must be part of any incident response posture for AWS best practices. Automating common response actions will reduce human error and accelerate remediation. AWS Lambda is a key service that enables event-driven automation for containing threats instantaneously upon detection. Automated incident response workflows are orchestrated with AWS Step Functions that ensure that complex responses are consistent. Additionally, these processes automate the tagging and isolation of compromised resources to prevent threats from spreading. Teams should also integrate automation with SIEM or SOAR platforms to streamline cross-team collaboration during incidents.
Recovery from incidents is a critical practice that focuses on restoring AWS resources and business operations to a secure state. Correspondingly, documenting root causes of incidents provides valuable insights for preventing recurrence. Subsequent post-incident reviews will further strengthen future response playbooks and improve overall cloud security posture.
AWS Services for Incident Response
Several AWS services form the building blocks for building an effective incident response posture with many best practices.
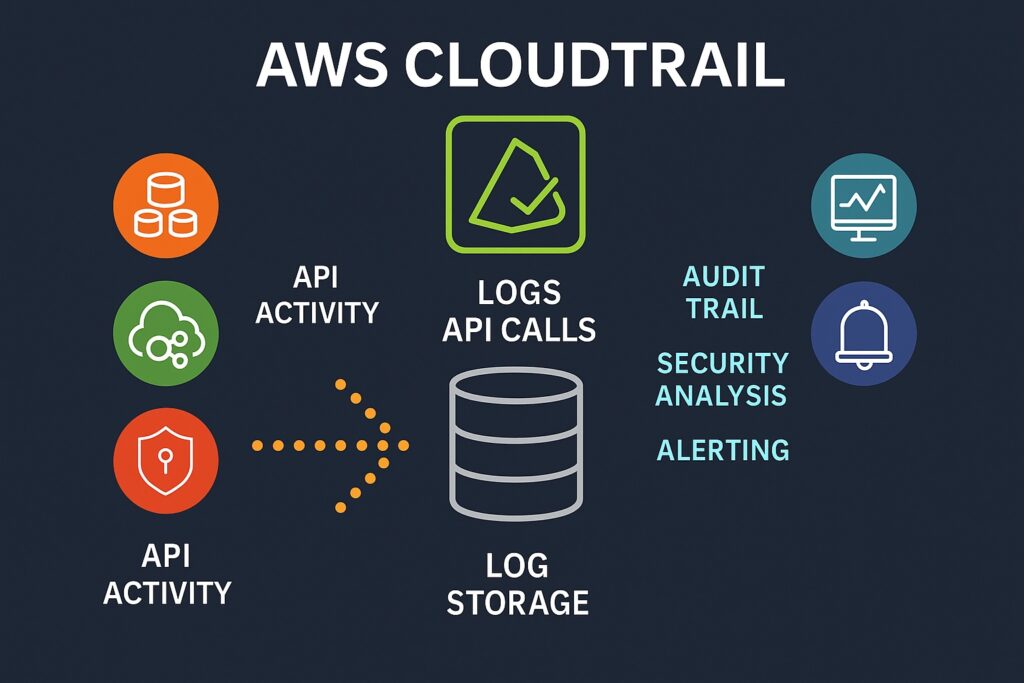
AWS CloudTrail
AWS CloudTrail records all API calls, and logging these calls is a vital best practice for an effective response when any incident occurs. These API calls provide a detailed audit trail for any incident investigation and enable the detection of unauthorized actions, such as suspicious IAM role changes. Also, organizations should centralize CloudTrail logs across accounts to ensure complete visibility. Organizations can easily achieve this by integrating CloudTrail with Amazon S3 for secure, long-term storage of evidence for compliance. The CloudTrail Insights service can highlight unusual patterns that may indicate compromise. Integrating this service with CloudWatch will enable near-real-time alerts on critical events.
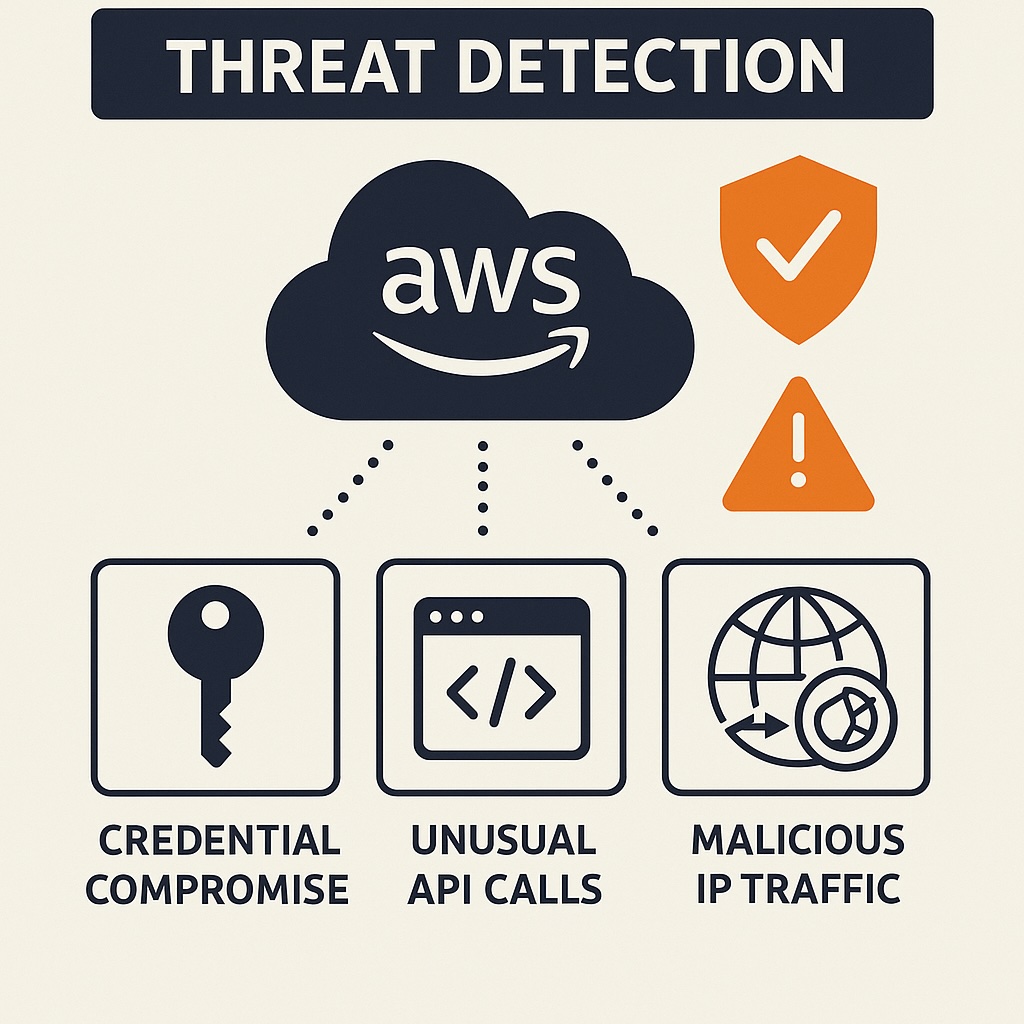
GuardDuty
GuardDuty builds on AWS CloudTrail, VPC flow logs, and DNS events to uncover suspicious activity, a critical incident response best practice. Specifically, it can detect threats such as credential compromise, unusual API calls, and malicious IP traffic. Additionally, GuardDuty can trigger automated responses through EventBridge and Lambda. Therefore, GuardDuty provides continuous monitoring to ensure detection of new threats without manual rule updates.
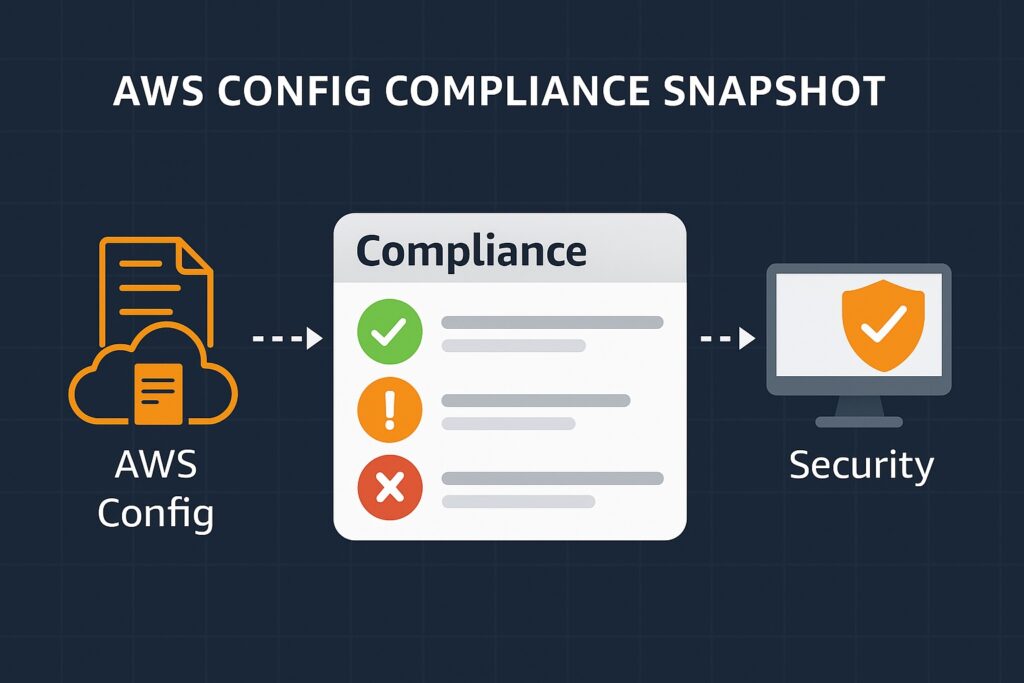
AWS Config
It is also essential to monitor resource configuration since configuration changes can result in potential security risks. AWS Config tracks these configuration changes, making it vital for best practices around incident response. It therefore enforces compliance by evaluating resources against predefined security rules. Often, resources drift from approved baselines, and it is critical to alert engineers to these occurrences. Additionally, config snapshots and history provide evidence during post-incident investigations. Furthermore, integrating AWS Config with AWS Systems Manager will enable automated remediation of noncompliant resources.
AWS Security Hub
There are disparate AWS services supporting incident response best practices, making it vital to integrate them into a single dashboard. Therefore, engineers can use AWS Security Hub, which aggregates findings from these services into a single dashboard, including GuardDuty and Inspector. Additionally, it prioritizes security alerts by using standardized security levels for more rapid triaging. Also, these automated insights highlight compliance gaps against frameworks like CIS and PCI DSS. Furthermore, integrating Security Hub with EventBridge enables orchestration of incident response workflows across accounts.

AWS Incident Response Best Practices
Given core principles and AWS services that support incident response, it is necessary to consider several best practices.
Build and Test Playbooks
Incident response actions must be consistent across the organization. Therefore, it is essential to document incident response playbooks to ensure consistent responses to any incident. Automation is a key element of any security posture. Hence, playbooks should map AWS service integrations, such as GuardDuty and Lambda, for automated responses. Additionally, organizations must ensure playbooks remain effective and relevant through validation by regular testing using simulations. Finally, organizations should also update playbooks following any incident to incorporate lessons learned into future responses.
Automate Detection and Response
Best practices around incident response must include an automated process utilizing AWS services. This is because they reduce manual effort and accelerate incident containment. AWS services that support automated incident response posture include EventBridge, which triggers Lambda functions to remediate threats in real time. Additionally, automation ensures consistent enforcement of security policies across AWS accounts. Also, integrating automation with monitoring tools will enable proactive threat management. Another benefit is the automated isolation of compromised resources that prevent attackers from escalating their access.
Enforce Least Privilege and IAM Guardrails
Unfettered access to an organization’s AWS resources is a sure way to invite bad actors. Therefore, any security posture limits access to only parties that need these resources. Hence, applying the principle of least privilege limits user access to only what is necessary, making it a best practice for AWS incident response. This is achieved through IAM service control policies (SCPs) that prevent actions that violate an organization’s security standards. Additionally, regular reviews of IAM roles and policies will help to eliminate unused or overly permissive access. Also, guardrails like MFA enforcement and key rotation will strengthen identity protection during incidents.
Integrate Monitoring with SIEM/SOAR
Incident response best practices for AWS are enhanced by integrating with a SIEM (Security Information and Event Management) platform and SOAR (Security Orchestration, Automation, and Response) tools. Integration of AWS logs with a SIEM platform provides visibility across environments. Meanwhile, SOAR tools enable the automated execution of playbooks to streamline incident handling. Additionally, correlating GuardDuty and CloudTrail findings in a SIEM platform helps to accelerate root cause analysis. Also, SIEM/SOAR integration supports cross-team collaboration by unifying security alerts and responses.
Sample Incident Response Workflow: Best Practices In Action
To see how best practices for incident response come together for AWS, it is best to consider a response workflow.
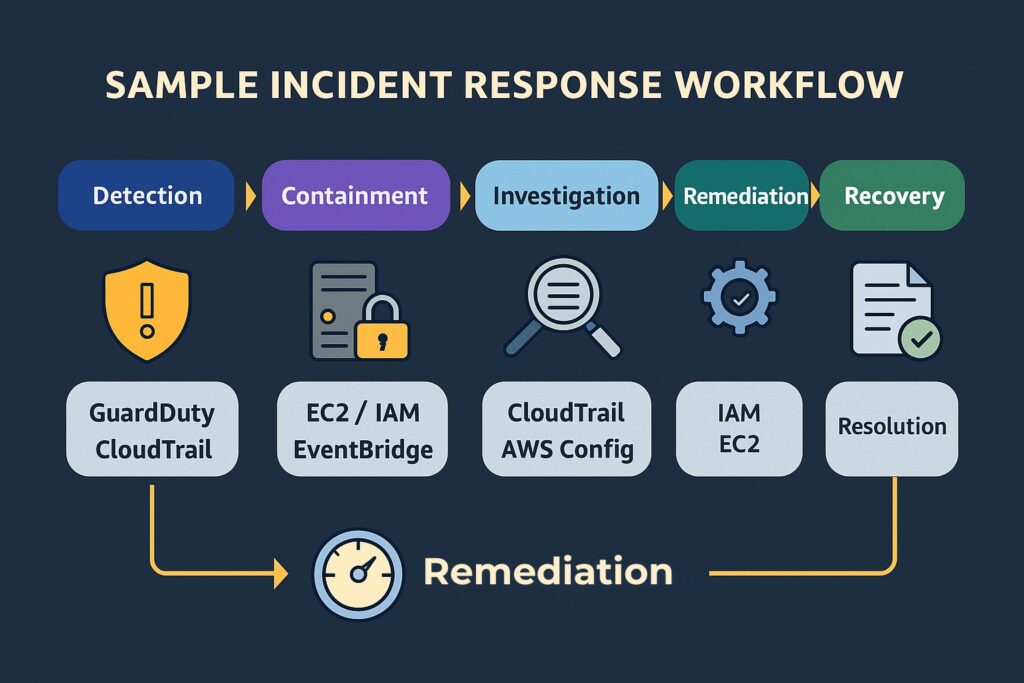
The first stage, detection, begins whenever GuardDuty or CloudTrail identifies any suspicious activity within the AWS environment. Security Hub aggregates these findings to provide a centralized view of the potential incident. Next, the containment stage involves isolating the affected EC2 instance or IAM credentials, preventing further compromise. Organizations can automate this stage by implementing EventBridge rules that trigger Lambda to quarantine resources instantly. The investigation stage then follows on from this, which utilizes CloudTrail logs and AWS Config snapshots to determine the scope of the incident. Investigators can use threat intelligence from GuardDuty findings to assist in confirming whether the activity was malicious or benign.
Engineers then perform remediation activities that include revoking IAM keys, patching vulnerable resources, or restoring from a secure baseline. The final stage is recovery, which ensures systems are returned to a fully operational and secure state. Subsequently, the organization documents lessons learned.
Example: EC2 Compromise Scenario
The following example illustrates this workflow in the following hypothetical event of an EC2 instance being compromised.
GuardDuty starts flagging unusual outbound traffic from an EC2 instance to a known malicious IP. Security Hub then surfaces this alert alongside related findings for the triage. Subsequently, EventBridge triggers a Lambda function that isolates the compromised EC2 instance from the VPC. Engineers then review CloudTrail logs to determine whether unauthorized IAM roles or API calls were made. They also examine AWS Config snapshots to help assess configuration drift that may have enabled the compromise. Next, engineers collect forensic data from the instance before termination to preserve evidence. Afterwards, the compromised EC2 is replaced with a clean, patched AMI to restore functionality. Post-incident activities include updating IAM roles and security groups to prevent similar attacks.
Challenges and Pitfalls
Along with best practices for incident response in AWS are challenges and pitfalls that engineers must understand.
Engineers and organizations must avoid overreliance on manual processes that slow down containment and allow threats more time to spread. Associated with delayed responses is human error in repetitive tasks that increase the risk of incomplete remediation of threats. Organizations are continually expanding the number of accounts in AWS, and scaling manual workflows across these multiple accounts is inefficient and inconsistent. Furthermore, delayed responses due to manual handling can result in greater business impact and downtime.
Organizations can easily miss gaps in cross-account logging where log collection is incomplete across accounts, leading to blind spots for incident detection. This provides an opportunity for attackers to exploit unmonitored accounts and escalate their privileges while undetected. Additionally, a lack of centralized logging complicates forensic investigations during incidents. Furthermore, gaps in logging can result in noncompliance with regulatory and audit requirements.
While engineers should avoid overreliance on manual processes, they can also make automation complex and unwieldy. Implementing automation requires time and effort, including upfront investment in design, testing, and integration. Specifically, making automated workflows unnecessarily complex can introduce unintended errors if not carefully validated. Likewise, scaling automation across multiple AWS services and accounts can increase operational overhead. But most importantly, misconfiguring automation can actually amplify security issues instead of containing them. For more on scaling challenges in AWS environments, see Handling Large Datasets in AWS: Scalable Solutions for Big Data Challenges
Future Trends in AWS Incident Response
AWS’s incident response best practices are continually changing as attackers find new ways to penetrate systems; therefore, it is a moving target.
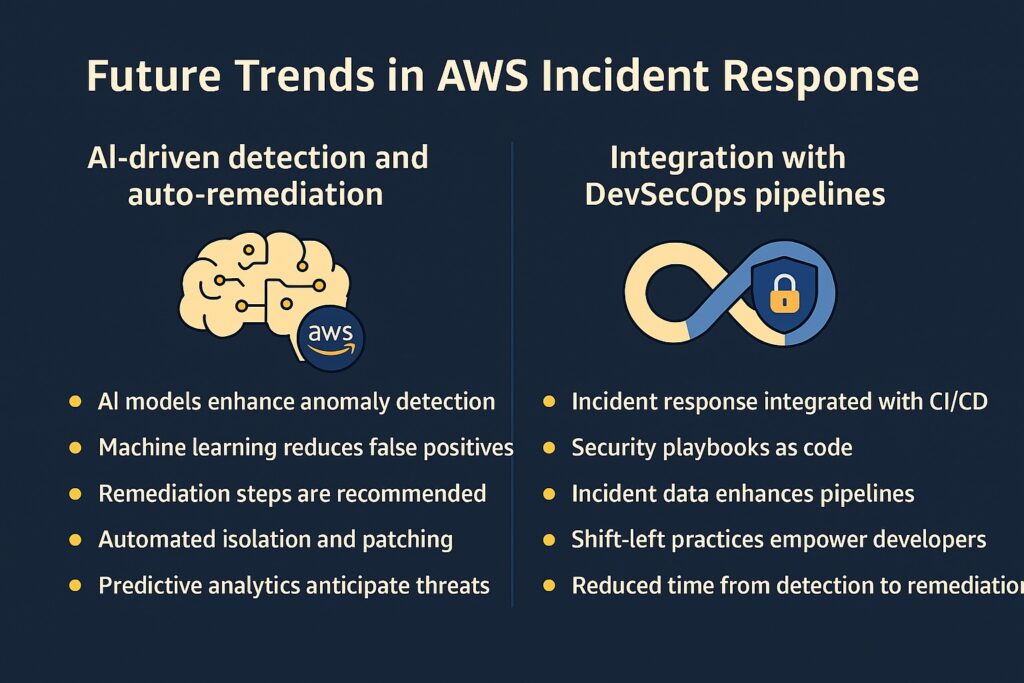
The field of AI is touching many activities, and cybersecurity is one area where it will have a profound impact. Engineers can build AI models that enhance anomaly detection by identifying subtle patterns in AWS logs. Also, they train machine learning to reduce false positives by refining threat detection over time. Additionally, AI-driven tools can recommend optimal remediation steps based on historical incidents. AI can also power automated remediation by isolating and patching compromised resources in real time. Other AI tools include predictive analytics that enable the anticipation of potential threats before they escalate into incidents. Finally, integration of AI with AWS services will streamline response workflows across hybrid and multi-cloud environments.
DevSecOps is a growing field, and integrating incident response with CI/CD pipelines will ensure security is built into the development lifecycle. These include automated checks that detect misconfigurations before workloads are deployed into production. Additionally, organizations can codify security playbooks as Infrastructure as Code for consistent enforcement. Another benefit is that incident response data is fed back into pipelines to improve security controls continuously. By employing shift-left practices, developers are empowered to resolve security issues earlier in the lifecycle. Therefore, seamless integration of incident response with DevSecOps will reduce time from detection to remediation across AWS environments.
Conclusion
When security engineers master AWS incident response best practices, they are equipped to handle real-world threats effectively. These practices align directly with the AWS Security Specialty exam, further reinforcing domain expertise. Security engineers should acquire hands-on familiarity with AWS services such as GuardDuty, CloudTrail, and SecurityHub. These are essential for both practice and certification. Therefore, continuous improvement in incident response strengthens cloud resilience while preparing engineers for exam success.
Continuous improvement strengthens cloud resiliency because it ensures that incident response strategies evolve with emerging cloud threats. This is achieved by regular reviews and updates to playbooks that enhance organizational resilience. Additionally, post-incident analysis provides valuable insights for refining security processes. Also, having ongoing improvements will foster a proactive security culture across engineering teams.
Further Reading
AWS Certified Security Specialty All-in-One Exam Guide (Exam SCS-C01) 1st Edition
by Tracy Pierce (Author), Aravind Kodandaramaiah (Author), Alex Rosa (Author), Rafael Koike (Author)
AWS Certified Security – Specialty (SCS-C02) Exam Guide: Get all the guidance you need to pass the AWS (SCS-C02) exam on your first attempt
by Adam Book and Stuart Scott
Cloud Security Handbook: Effectively secure cloud environments using AWS, Azure, and GCP 2nd ed. Edition
by Eyal Estrin (Author)
Incident Response in the Age of Cloud: Techniques and best practices to effectively respond to cybersecurity incidents
by Dr. Erdal Ozkaya (Author)
Practical Cloud Security: A Guide for Secure Design and Deployment, 2nd Edition,
by Chris Dotson (Author)
Affiliate Disclosure: As an Amazon Associate, I earn from qualifying purchases. This means that if you click on one of the Amazon links and make a purchase, I may receive a small commission at no additional cost to you. This helps support the site and allows me to continue creating valuable content.