
Introduction
What is not spoken about is the apparent slowdown in LLM innovation. LLM innovation slowdown explained considers the factors responsible for this and the realistic path forward.
Neural network research and applications have progressed for many decades in spite of enduring many AI winters. Its viability had to cross a certain threshold of efficacy for mainstream acceptance and adoption. That moment came at the end of 2022 when the Transform neural network architecture reached human-like text generation maturity. This level of maturity enabled AI accessibility to everyday users, not only researchers in the lab. It demonstrated great versatility in writing, coding, and analysis, taking the world by storm. This triggered an AI investment boom where startups and enterprises were rushing to integrate LLMs into their operations.
What the world witnessed in this revolution is LLMs picking up all the low-hanging fruit in their abilities. Therefore, they made astonishing gains as the world experienced LLM mania. Many were making bold and exaggerated claims that Artificial General Intelligence was around the corner. Also, these LLMs will surpass human intelligence in a matter of months. However, what is now hushed is that LLM innovation is slowing despite early gains. With LLM innovation slowdown explained, we can show the historical factors leading to this slowdown.
LLM innovation slowdown explained will consider factors common across all major technological innovations. As with previous technological innovations, everyone would say that they were different, and the same has happened with LLMs. However, all have fallen victim to real-world limits, technology S-curves, and hype cycles, while quietly mapping realistic future paths. LLM innovation is no different, and we are already seeing similar patterns emerge.
The Rise of LLMs and the Initial Innovation Boom
Before we have LLM innovation slowdown explained we need to review LLMs recent history.
LLM’s underlying technology is a neural network architecture that has the name Generative Pre-trained Transformer (GPT). A 2017 paper titled “Attention is All You Need,” introduced this architecture within natural language processing research.
OpenAI built a series of these GPT models, starting with GPT-1 and GPT-4 the current state of the art. Similar to Microsoft Windows 1.0 and 2.0, GPT-1 and GPT-2 were more laboratory novelties garnering very little attention. It was the improvements with GPT-3 that stunned the world with its ability with its human-like text generation. Along with human-like text generation, it had high fluency and general knowledge surpassing humans. Its first killer app was computer code generation and coding support.
Along with its impressive abilities came all the wild predictions that AI Armageddon was around the corner. We also started hearing that these tools will quickly morph into Skynet, making the human race extinct. These events have not taken place indicating that there is an LLM innovation slowdown.

Everyone Jumps on the Bandwagon
Other startups and established companies were also progressing their own GPT models. It was advances in the underlying technologies that allowed these models to mature into seriously everyday applications. GPUs were the main underlying technologies with Nvidia being the main supplier. Soon these models were also demonstrating high fluency and superior general knowledge and also generating computer code. These include Claude by Anthropic and Gemini by Google.
Overnight they had widespread and rapid adoption with Microsoft introducing GitHub copilot for software engineering. Enterprises were very quickly deploying AI and there was the rise of open-source LLMs led by Meta.
All of these led to very high expectations and a boom in AI investment. Many of the industry leaders led by Sam Altman were further talking up the ongoing spectacular advances in LLMs.
Signs of the Slowdown: Where Progress Is Losing Steam
OpenAI has done a stellar job of sweeping diminishing returns under the carpet and practising the art of “vaporware” prevalent in the 90s. When OpenAI first announced that GPT-4 was coming soon with the “you ain’t seen nothing yet” tagline, the world was holding its breath! Commentators were predicting that AI would replace everyone’s job within a few short years or even months. However, when GPT-4 was ready for release, OpenAI quietly slipped it in with little fanfare while making other announcements. A technique known in political circles as “putting out the trash”.
Whereas GPT-4 was a definite improvement over GPT-3, it was not the earth-shattering change that everyone was anticipating. They played the conjurer’s trick of diverting everyone’s attention away from GPT-4.
Actual Improvements According to LLM Innovation Slowdown Explained
Its major feature enhancement was its performance on standardized tests like the bar exam and SATs. LLM innovation slowdown explained shows that LLM enhancements resembled bug fixes and minor feature enhancements with new software releases. These were addressing accuracy and consistency issues experienced with GPT-3 along with reducing hallucinations with LLMs. Hallucinations were the real dampener on the excitement around this new technology.
There is the continual exponential improvement in hardware, especially with GPUs, following Moore’s Law. Subsequently, there was an expectation that there would be an exponential improvement in LLMs. However, with computing technologies of the past, this did not necessarily transform into computing efficacy. The same is observed with LLM improvements, while significant, there is not the exponential improvement anticipated. In fact, we have observed diminishing returns in LLM and image generation improvements. Even though we have larger models and higher-performing hardware.
Ironically, instead, we have witnessed costs rising exponentially, and these AI companies have a continually growing appetite for capital. LLM innovation slowdown explained points out that, instead, there are decreasing marginal improvements.
What is becoming more apparent are frustrations with these models, similar to the software crisis during the sixties and seventies. Issues like hallucinations and brittleness have tarnished the gloss of the models. Also, many are realising that these models do not perform true reasoning but often give the illusion of this.
Understanding the S-Curve for LLM Innovation
The S-curve has accurately described technological innovations in the past, and we can use it to predict the path of LLM Innovation. It describes the progress of new technologies from their initial rapid growth till they eventually plateau. They experience early breakthroughs that often lead to explosive and exponential gains with the excitement of rising expectations. However, as time progresses, each new improvement yields smaller returns for similar or greater effort. Eventually, this curve flattens as the technology matures and reaches real-world limits. Most of the innovations in history have followed this pattern, ranging from semiconductors to smartphones. It is likely that LLMs will also follow this trajectory.
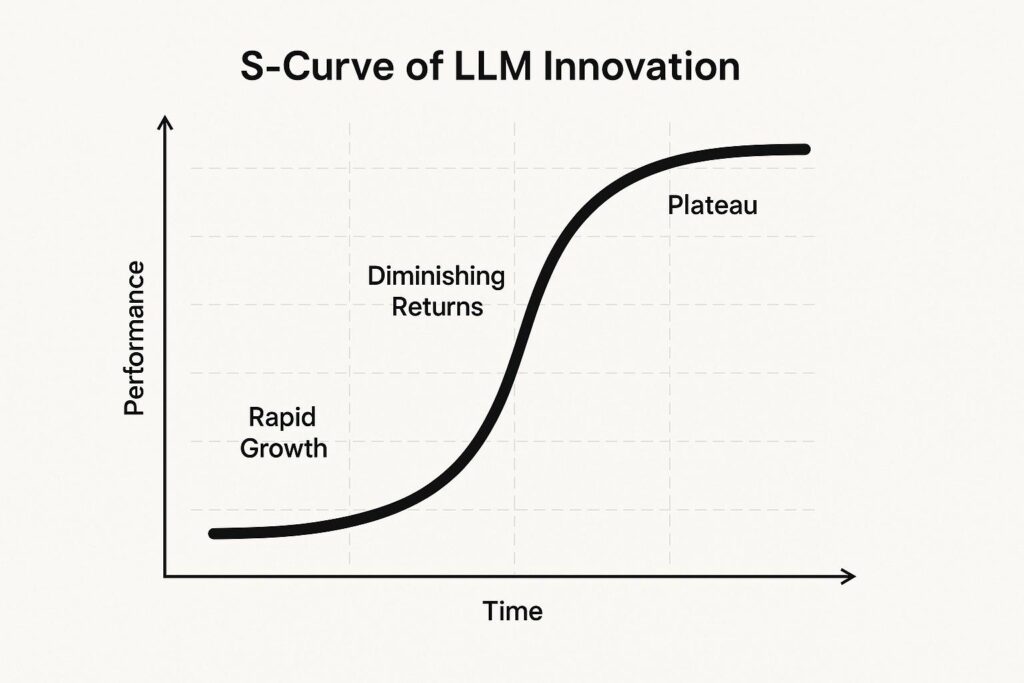
When development started with the GPT model, there were explosive early gains in fluency, coherence, and versatility. This happened with each new release leading up to GPT-3. The release of GPT-3 heralded a breakthrough moment where it delivered capabilities that astounded both users and experts. GPT-4 on the other hand, while a superior product, exhibited smaller improvements despite higher costs and larger model size. We are now seeing that each new generation is demanding much more data and computing resources for diminishing improvements. This has not only happened for ChatGPT but for competitors’ models as well, like Gemini and Claude.
It is possible that this current generation of LLMs is quickly approaching the plateau of their S-curve. Deep-Seek, although impressive, may only be tweaks of the low-hanging fruit of this generation. This is similar to semiconductors, where early advances brought rapid gains in processing power and miniaturization. However, even though semiconductors consistently followed Moore’s law for many decades, they still hit S-curve limits. These included heat dissipation, quantum tunneling, and rising fabrication costs. We are seeing a similar trajectory with LLMs, which we will explore next.
Why Bigger Models Aren’t Always Better
Building larger models will not address LLM innovation slowdown since these models’ capability will not grow exponentially. On the contrary, these models need exponentially more data and computing power to train. Therefore, the outcome is that marginal quality improvements are shrinking despite the massive engineering efforts invested in these models. This is translating into larger and larger budgets with training costs for these cutting-edge models running into tens or hundreds of millions of dollars. We have to ask the question of whether minor gains or factual accuracy actually justify the growing investment. In fact, this growing imbalance is signalling that we may be chasing diminishing returns at unsustainable costs.
We will consider these costs and resource demands in greater detail. Larger models mean larger GPU clusters and greater energy consumption in both training and running these models. We have already seen these putting enormous strains on our energy infrastructure and data centers. We have many cloud providers now racing to reestablish nuclear energy as a viable alternative. Given this large investment, it means that only a handful of companies can compete, resulting in a high concentration of AI power. The debate on environmental impact is becoming louder, just as it is for cryptocurrencies.
For more on scalable processing and efficient data workflows, see our Apache Spark Big Data Analytics Guide.
Model Efficiency for LLM Innovation
Given these costs associated with bigger models, researchers have started focusing on model efficiency rather than model scale. Organizations are also exploring smaller models that are fine-tuned to specific tasks that yield better performance at less cost. Another technology, Retrieval-Augmented Generation (RAG), allows models to pull in external knowledge dynamically without training. In summary, these model enhancements look to reduce the need to store vast amounts of static data within parameters.
We have considered the limiting factors of model sizes with LLM Innovation slowdown and will now look at real-world limits.
Real-World Limits: Data, Reasoning, and Common Sense
A significant hurdle to addressing LLM Innovation slowdown is the training data itself. Model training has already scraped most of the publicly available internet data and text, reaching a potential training data shortage. Any additional data may prove redundant than providing any meaningful learning gains. This is apparent since the internet contains massive amounts of low-quality, biased, or duplicated content, making this challenging for data scientists. We have most likely reached the point where increasing data volume will not guarantee better performance or reasoning. Any future improvements will depend more on data quality and curation than on raw quantity.
LLM innovation has greatly touted that these LLMs will soon have the ability to perform reasoning. However, while LLMs have perfected pattern recognition, they do not have a genuine understanding. This is apparent when they hallucinate over some of the simplest questions. While they can generate convincing answers, they have not grasped the underlying logic. This is demonstrated when basic reasoning tasks trip up models over phrasing or contextual shifts. True reasoning requires structured thinking and not just powerful statistical correlation. The problem is that we get an illusion of intelligence from their human-like fluency, but not from their actual comprehension of what they are saying.
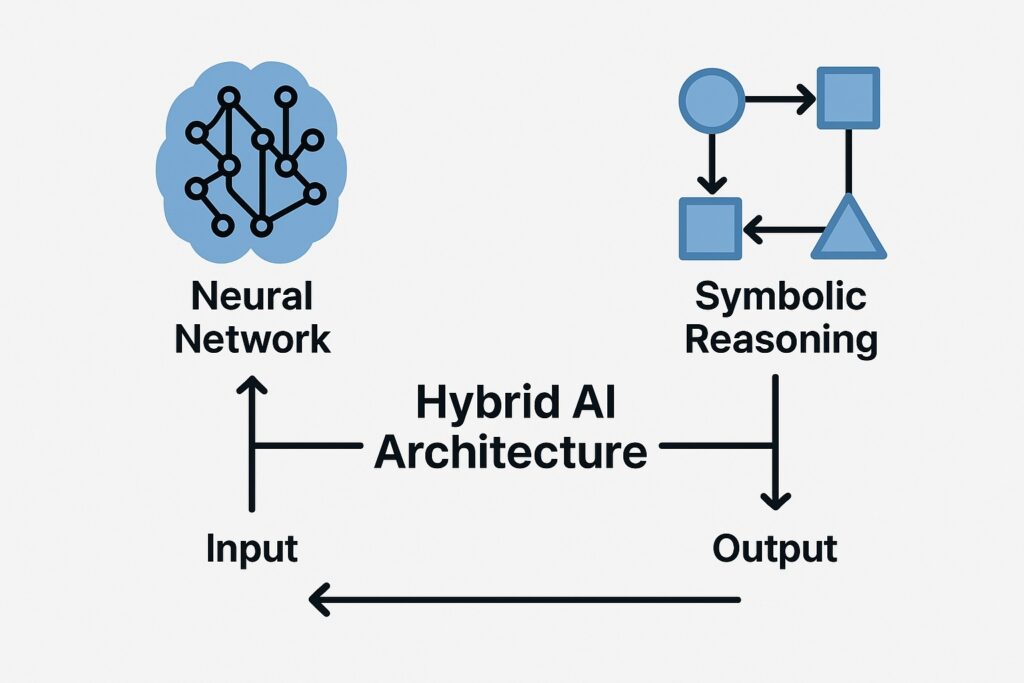
Therefore, we have seen that current LLMs struggle with logic, planning, and abstraction beyond surface-level text. We may need to build hybrid models by combining neural nets with symbolic reasoning if AI is to offer deeper understanding. Any future breakthroughs, and not just incremental improvements, may come from combining LLMs with other AI technologies.
What the Slowdown Means for the Future of AI
Even with the fanfare of ChatGPT, the real LLM innovation revolution is where AI tools are quietly becoming utilities. They are following a similar path that spreadsheets and search engines have before them. They are actually slipping into daily workflows as a silent assistant for humans instead of replacing them. The true impact of AI tools will be their unobtrusive integration, like all other transformative technologies before them.
We have started to see that raw model size is not producing the efficacy gains hoped for. Therefore, the next progress wave will emphasize smarter integration. Hence, efficiency gains are more important than brute force scaling seen with Deep Seek’s model. Apart from more generic and general-purpose models, there will be a shift to fine-tuned, task-specific agents. This was witnessed in the early eighties, when PCs began to assume many tasks that were the domain of large timesharing systems. Our innovation will therefore shift from large foundation models to their application and orchestration.
Early factory automation generally replaced all the humans with machines and was an abject failure. More successful factories effectively paired humans with robots, and the same is true with the current wave of AI. Even LLMs struggle with nuances, context, or ethics, and it is better for AI to augment human capability and not replace it. Organizations will inevitably fail if they try to chase full autonomy instead of investing in collaboration.
The Next LLM Innovation Wave?
LLMs have put AI on the map as a central part of workflows and no longer on the fringe. It is unlikely that we will experience another AI winter, but we could be headed for an AI bust just like the internet boom. Just after the internet bust, there was a new wave of innovations. There is likely to be a new wave of AI innovations, but their architectures will be radically different and not simply larger LLMs.
Conclusion
While considering LLM innovation slowdown, we saw that the GPT reached critical mass, attaining a stunning level of fluency. It demonstrated both human-like conversational capability along with in-depth knowledge, stunning many critics. However, its further development was far more subdued than what was anticipated, even though they have made many substantial improvements.
Many may write LLMs off as failing to meet ongoing expectations. However, this is the path that all previous innovations followed, and LLMs are now showing signs of maturity. The emphasis is now shifting to smarter design decisions and deployments rather than depending on increasing raw computing power.
The challenge is now for organizations to figure out how to utilize LLMs as tools to improve productivity more effectively. This is the challenge for all of us than waiting for the next magical leap.