Introduction
The key benefit of Amazon SageMaker training jobs is that engineers can train machine learning models at scale. Equally important is that they do not need to manage infrastructure. Additionally, they support popular ML frameworks like TensorFlow, PyTorch, and XGBoost with prebuilt or custom containers. Therefore, engineers can launch distributed training on powerful GPU or CPU instances with only a few lines of code.
SageMaker’s power lies in its ability to automatically handle provisioning, scaling, and tearing down compute resources. Subsequently, training jobs integrate tightly with other AWS services, such as S3, for seamless data input and model output storage. Additionally, engineers can monitor training progress through CloudWatch logs and built-in metrics dashboards.
👉 New to SageMaker? Start with our SageMaker overview guide for ML engineers to understand its core features, supported services, and practical benefits before diving into training jobs.
SageMaker also provides a range of tools, including debugging tools such as SageMaker Debugger, that help identify training issues in real-time.
SageMaker enables engineers to reduce costs and improve resiliency through the use of Spot Instances and Checkpointing.
This article guides the reader through setting up, optimizing, and monitoring a SageMaker training job. Additionally, they will learn best practices for script organization, resource usage, and reproducibility.
Understanding SageMaker Training Jobs
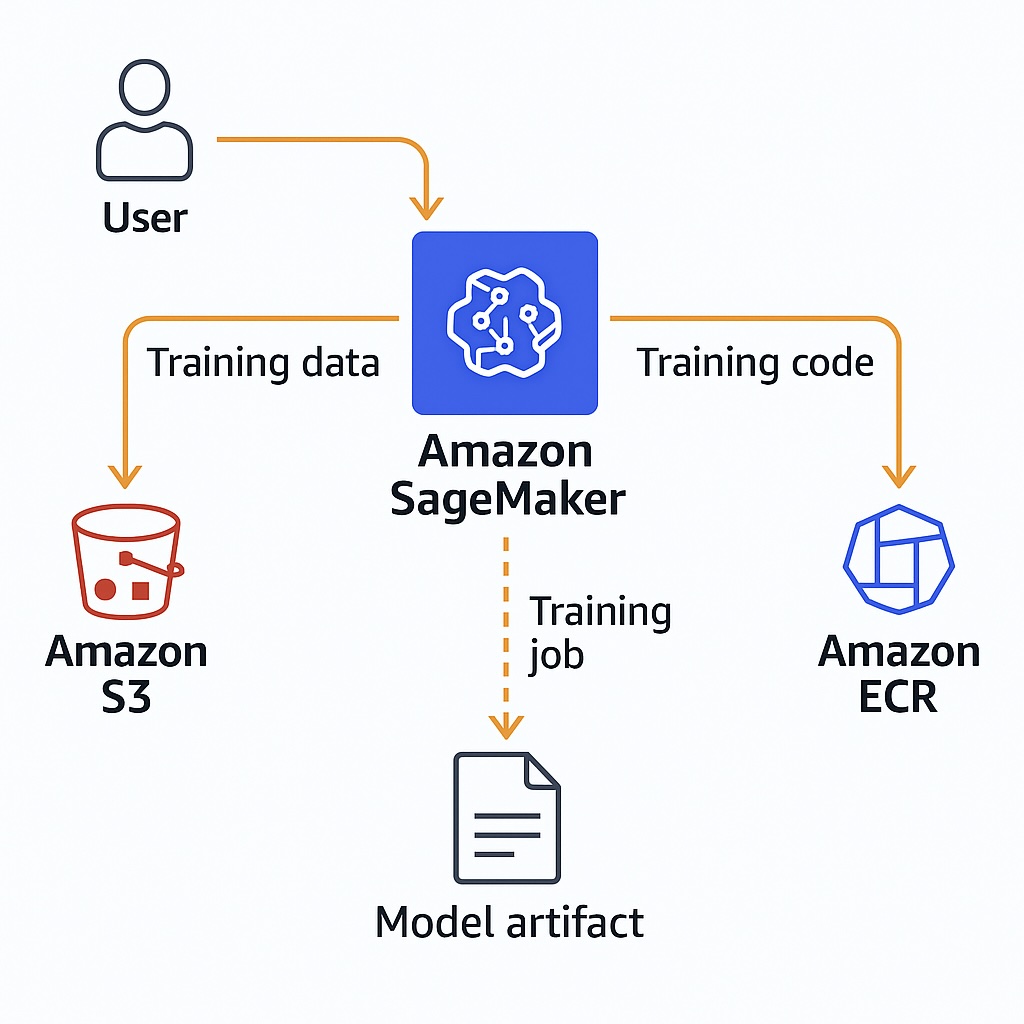
What Is a SageMaker Training Job?
By definition, a SageMaker training job is an AWS-managed process that runs user-defined ML training code on AWS infrastructure. Specifically, it is responsible for automating the provisioning of compute instances, data loading, model training, and output storage. Therefore, an engineer can define the jobs using an estimator object that specifies the algorithm, input data, and training script. Subsequently, when launched, the SageMaker job handles orchestration, monitoring, and teardown without manual intervention.
Key Components: Estimator, Script, and Input Data
These comprise SageMaker jobs along with other minor components. The Estimator is the starting point for defining how SageMaker runs the training job along with the framework, hyperparameters, and compute resources. Next, the training script contains the actual ML code that is run in a training job. This typically includes steps such as data loading, model definition, training loop, and output logic. Lastly, the input data is typically stored in Amazon S3 and passed to the training script via input channels. Furthermore, estimators automatically handle uploading scripts and dependencies to the training environment. Engineers can also customize the entry point, Python version, and source directory to match the project structure.
Choosing the Right Instance Type for SageMaker Training Jobs
An essential benefit of using SageMaker training jobs is that they offer a wide range of instance types provided by AWS. These include CPU-based instances, such as ml.c5, and GPU-based options, such as ml.p3, which are suitable for different workloads. Particularly, GPU instances suit deep learning models while CPU instances are better suited to smaller or classical ML tasks. Engineers should also consider memory, vCPU/GPU count, and cost to match their model size, training time, and budget.
Input and Output Channels: Managing Data Flow
Data flow is essential for efficient SageMaker training job operations. Therefore, input channels must map S3 URIs to directories in the training container. Ensuring that datasets are accessible to training scripts. Thereupon, SageMaker automatically downloads the input data before training commences and uploads the model artifacts upon training completion. Additionally, engineers can define multiple input channels (e.g., train, validation) to structure their data workflow clearly.
Spot vs On-Demand Training: Cost and Reliability Trade-Offs
SageMaker also allows engineers to select either Spot or On-Demand instances for their compute nodes. Spot instances offer up to 90% cost savings but can be interrupted if AWS needs the capacity. Conversely, On-Demand instances provide stable, uninterrupted training runs at a higher hourly cost.
Setting Up a SageMaker Training Job (Step-by-Step)
This comprises three primary stages of setting up a script, configuring the estimators, and launching the training job. We will explore each of these in detail below.
Training script setup
This is the first and a key part of launching a SageMaker training job, especially when we need custom training logic. It comprises several substeps in building the script that runs within the container that SageMaker provisions, ready for Estimator configuration. The training script is executed with the final stage that launches the training job. This is the breakdown of actions that the training script performs when executed.
Define Argument Parsing
There are the arguments passed into the training job by SageMaker when it executes it. These include hyperparameters and file paths, as shown in the code example below.
import argparse parser = argparse.ArgumentParser() parser.add_argument('--epochs', type=int, default=10) parser.add_argument('--batch-size', type=int, default=32) parser.add_argument('--model-dir', type=str) parser.add_argument('--train', type=str) parser.add_argument('--validation', type=str) args = parser.parse_args()
Load Training and Validation Data
Using the paths that SageMaker passes in from the previous step, we write code to load the data. This is usually from S3, and this data is loaded into local memory for training and validating the model.
import os import pandas as pd train_data = pd.read_csv(os.path.join(args.train, 'train.csv')) val_data = pd.read_csv(os.path.join(args.validation, 'val.csv'))
Define the Model Architecture
The script here sets up the appropriate framework (e.g., PyTorch, TensorFlow, scikit-learn) to define the model. Below is an example using PyTorch in defining a feedforward model or single-layer linear classifier within SageMaker for the training job.
import torch.nn as nn class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.fc = nn.Linear(10, 2) def forward(self, x): return self.fc(x)
Train the Model
Here, the script sets up the training loop, loss function, optimizer, and metrics, and then executes the training loop. The code below shows the code performing these actions prior to running the training loop.
import torch.optim as optim model = Net() optimizer = optim.Adam(model.parameters(), lr=0.001) criterion = nn.CrossEntropyLoss() # Typical PyTorch training loop goes here...
Save the Trained Model
Write code to save the trained model to the location provided by SageMaker, typically located in S3. The code below shows how to save a PyTorch model using the path provided.
import joblib import os model_output_path = os.path.join(args.model_dir, "model.pth") torch.save(model.state_dict(), model_output_path)
Estimator configuration
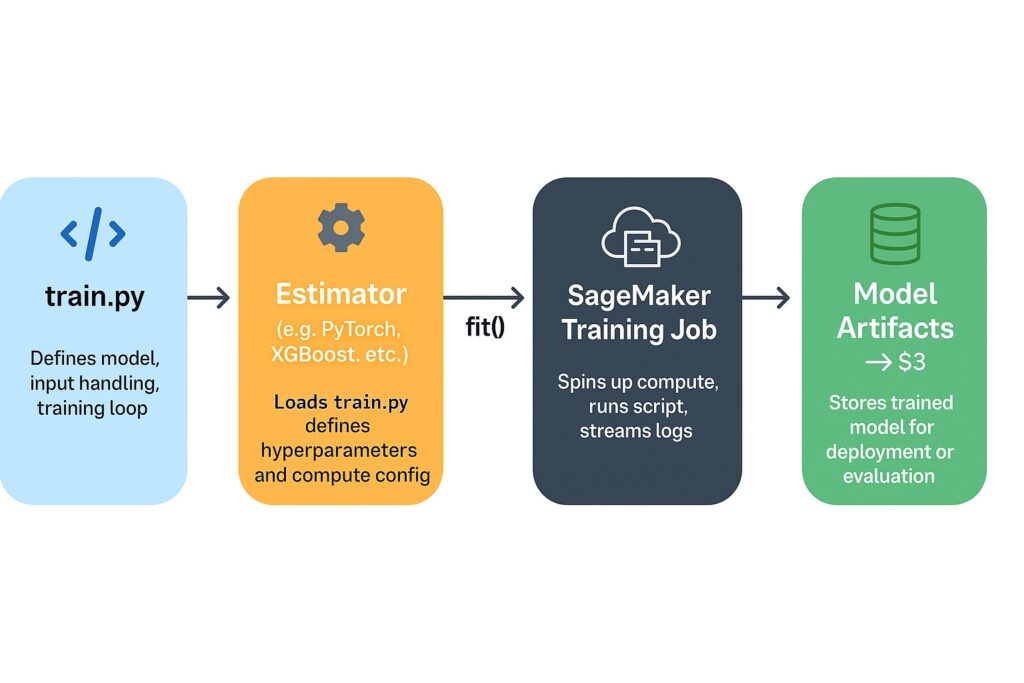
The Estimator configures how SageMaker will train the model within the training script. This is in contrast to the training script that contains the actual ML code that runs during training. The Estimator code typically resides in the engineer’s own Python environment, which is one of several places. Firstly, it can reside in a Jupyter notebook in SageMaker Studio. Secondly, it can be a Python script running locally or on an EC2 instance. Lastly, in a Pipeline stage within a SageMaker Pipeline definition.
Configuring an estimate is done as follows:
Select the Matching Estimator class
Here, the engineer selects the estimator that matches the framework they are using, which is either a built-in framework, or BYO container, or a custom image.
from sagemaker.pytorch import PyTorch
Set the Entry Point and Source Directory
The entry point specifies the path to the training script, while the source directory is an optional folder containing supporting code.
entry_point='train.py', source_dir='src',
Specify Compute Computation
This sets how SageMaker should provision training resources, including the type of EC2 instances and the number of instances. It also specifies the size of the EBS volumes and the timeout in seconds.
instance_type='ml.m5.xlarge', instance_count=1,
Set the Framework Version and Python Version
It is essential to ensure compatibility between the ML code and the runtime environment.
framework_version='1.13.1', py_version='py39',
Define the IAM role
This is the SageMaker execution role that allows access to other AWS resources, including S3 and CloudWatch.
role = 'arn:aws:iam::123456789012:role/SageMakerExecutionRole'
Specify Output Location
This is the location for the trained model artifacts, which is typically an S3 bucket.
output_path='s3://my-bucket/output',
Set Hyperparameters
These are passed to the training script via argument passing.
hyperparameters={
'epochs': 10,
'batch-size': 32
}
Example
from sagemaker.pytorch import PyTorch estimator = PyTorch( entry_point='train.py', source_dir='src', role=role, instance_type='ml.c5.xlarge', instance_count=1, framework_version='1.13.1', py_version='py39', output_path='s3://my-bucket/output', hyperparameters={ 'epochs': 5, 'batch-size': 64 } )
Launch the SageMaker Training Job
This occurs typically within a Jupyter notebook, Python script, SageMaker Studio environment, or SageMaker Pipeline. It initiates the fully managed SageMaker process that trains the model based on the script and configuration already set.
Passing Input Data Channels
The engineer calls the .fit() function with either an S3 URI or a dictionary of input channels. This instructs SageMaker what to download into the container and map to paths like /opt/ml/input/data/train.
Packaging the Script and Dependencies
SageMaker now:
- Uploads the training script from the entry point
- Uploads the optional source directory dependencies
- Prepares a training container with these files and configurations
Provisioning Infrastructure
Using the instance type and instance count, SageMaker
- Launches the required EC2 instances
- Sets up networking, security roles, and file system access
Running the Training Script
Within the container, SageMaker:
- Passes hyperparameters and file paths to your script via the command-line arguments
- Executes the training script using those values
- Saves the model artifacts to /opt/ml/model and uploads to S3 upon completion
Job Monitoring and Logging
During job execution, SageMaker:
- Streams logs to CloudWatch
- Tracks job status via the SageMaker console or SDK
- Supports tools like Debugger and Profiler
Shutting Down Resources
Upon completion of training or training job failure, SageMaker tears down the compute instances. However, logs and artifacts remain available for inspection to assess the SageMaker training job.
Monitoring and Debugging Your SageMaker Training Jobs
SageMaker training jobs are rarely complete the first time around. Therefore, engineers often need to monitor and debug their training jobs to resolve any issues. SageMaker and AWS provide several tools and processes that allow engineers to find and resolve any problems.
CloudWatch
CloudWatch is an AWS service that seamlessly integrates with SageMaker. It automatically collects logs from each SageMaker training job’s standard output and error streams in real time. Subsequently, ML engineers can use these logs to troubleshoot issues, track progress. Additionally, they can verify that hyperparameters and data paths are correct. Also, CloudWatch Metrics provides visualizations for key indicators like loss, accuracy, and resource utilization over the duration of the job.
Log Streaming
In addition to CloudWatch, SageMaker can stream logs from training jobs directly to notebooks or terminals during execution. These real-time logs help engineers monitor progress, view custom print statements, and trap early warnings. Additionally, they are also saved simultaneously to AWS CloudWatch for persistent storage and future analysis.
SageMaker training job metrics
Using CloudWatch, SageMaker automatically publishes training job metrics including loss, accuracy, and epoch progress. Consequently, engineers can use these metrics to help evaluate model performance over time and detect convergence issues during training. Additionally, engineers can log training metrics from their scripts using the print() command in specific formats recognized by SageMaker.
SageMaker Debugger
SageMaker Debugger automatically captures tensors and system metrics during training for ML engineers to perform in-depth inspection. Additionally, it enables real-time monitoring of parameters such as gradients, weights, and loss values. Therefore, engineers never need to modify their training scripts. Also, engineers can define custom rules or built-in ones to detect training issues such as vanishing gradients or overfitting. SageMaker Debugger stores its outputs in AWS S3, allowing engineers to analyze them using SageMaker Studio or third-party tools like TensorBoard.
Cost Optimization Strategies

There is plenty of scope with SageMaker Training Jobs to manage cost with various configurations.
Spot Instances
Spot Instances is where AWS lets engineers use excess EC2 instances for up to 90% cost reduction. However, whenever they are needed as demand instances, AWS reclaims them within two minutes interrupting all work. Spot Instances are available with SageMaker for training jobs allowing significant costs reductions during training. Managed Spot Training in SageMaker automatically handles instance interruption and rescheduling. It also enables engineers to monitor interruption rates and fallback behavior using CloudWatch metrics and SageMaker job statuses.
Reduce Job Time
Reducing job time will shorten the time that SageMaker training processor resources are run and minimize costs. Engineers can reduce job time by speeding up data loading with optimized data formats like RecordIO or Parquet. Another strategy is to accelerate training by leveraging GPU instances for compute-intensive deep learning models. Also, engineers can tune batch size and learning rates for faster convergence without compromising accuracy. Finally, similar to using profiling tools in software performance enhancement, engineers can use SageMaker Profiler. This enables them to identify bottlenecks and optimize resource usage.
Enable Checkpointing
Since AWS can interrupt Spot Instances, engineers will want to preserve progress to restore model training. Therefore, they configure SageMaker to save model checkpoints to S3 at regular intervals during training. Engineers should also ensure their training scripts support resume logic to reload from latest checkpoint after interruption.
Early Stopping
Another cost reduction strategy is halting training when the validation loss stops improving. Engineers can implement this logic in their training scripts and thereby avoid any unnecessary training epochs once they reach optimal model performance.
Best Practices for SageMaker Training Jobs

Similar to software engineering, SageMaker Training Jobs have their counterpart in best practices.
Script versioning
Training job scripts are code, and engineers should manage these using a version control tool, Git, to track changes over time. Additionally, ML engineers should tag script versions that correspond to specific training runs to enable reproducibility. Also, these should have traceability through commit hashes or version numbers. Finally, engineers should store scripts and dependencies in a structured directory to support consistent packaging and reuse.
Dataset Partitioning
A key difference from software engineering is that datasets are an essential component of SageMaker training jobs. These are used to train and evaluate model performance accurately, and engineers must split these into training, validation, and test sets. Moreover, to prevent bias in training or evaluation, engineers should ensure partitions are representative and randomly shuffled. Additionally, engineers should ensure clean input channel mapping by placing each partition in a separate S3 prefix or path (e.g., train/, validation/, test/). Finally, engineers should consider stratified sampling for classification tasks.
Reproducibility
Given the non-deterministic nature of machine learning, reproducibility is highly critical in training ML models. Engineers should set random seeds in their training scripts to ensure consistent results across runs, thereby making the training deterministic. Additionally, they should log hyperparameters and environment details for each job to enable exact re-creation. Also, it is critical to pin framework and library versions to avoid unexpected behavior from software updates. Moreover, SageMaker Experiments is available that can track inputs, outputs, and metrics from each training run.
Naming Conventions
Similar to software engineering, consistent naming conventions are a core best practice for SageMaker Training Jobs. Even though these are used to train machines, humans still maintain these scripts; therefore, readability is critical. Therefore, engineers should use descriptive and consistent job names to identify experiments and model versions easily. Additionally, engineers should include timestamps or version numbers in job names for chronological tracking. Also, it is essential to incorporate key metadata, such as model type or dataset name, into training job identifiers. Finally, engineers must avoid special characters and spaces to ensure compatibility with AWS resource naming rules.
Tagging
AWS tags are a powerful tool for managing AWS resources, and engineers can use these to label SageMaker training jobs. These tags include project names, environments, or owners for easier management. Additionally, organizations can enable cost allocation tagging to track and optimize SageMaker usage across teams or workloads.
SageMaker Training Jobs Conclusion
The key advantage of using SageMaker Training Jobs is seamless integration with AWS and simplified model training without manual infrastructure management. The core components of each SageMaker training job are estimators, training scripts, and input data. However, engineers must manage training costs primarily through choosing the right instance type and using Spot Instances whenever possible. Additionally, they can improve efficiency and reliability through proper script organization, dataset partitioning, and checkpointing. Furthermore, to track performance and troubleshoot issues, there are monitoring tools like AWS CloudWatch and SageMaker Debugger. Also, there are best practices to follow, including reproducibility, cost optimization, and smoother collaboration.
Engineers also want to avoid unnecessary computation time and costs by using early stopping and profiling tools. They should also ensure consistent naming conventions and tagging to enhance job traceability and resource organization.
In summary, SageMaker’s managed training workflow supports both experimentation and production readiness at scale.
Further Reading
Amazon SageMaker Cookbook: Practical Solutions for Using Machine Learning and Deep Learning Services
Joshua Arvin Lat
Practical Deep Learning on the Cloud: With Keras, TensorFlow, and Amazon SageMaker
Alok Dhariwal
Machine Learning Engineering with Python: Manage the production life cycle with MLOps
Andrew P. McMahon
Learn Amazon SageMaker: A Guide to Building, Training, and Deploying Machine Learning Models
Julien Simon
Data Science on AWS: Implementing End-to-End, Continuous AI and Machine Learning Pipelines
Chris Fregly & Antje Barth
Machine Learning with AWS: Explore the power of ML and AI on AWS
Jeff Martineau
Disclosure: As an Amazon Associate, I earn from qualifying purchases.