
Introduction: GuardDuty Findings Explained
Why GuardDuty Findings Are Central to AWS Threat Detection
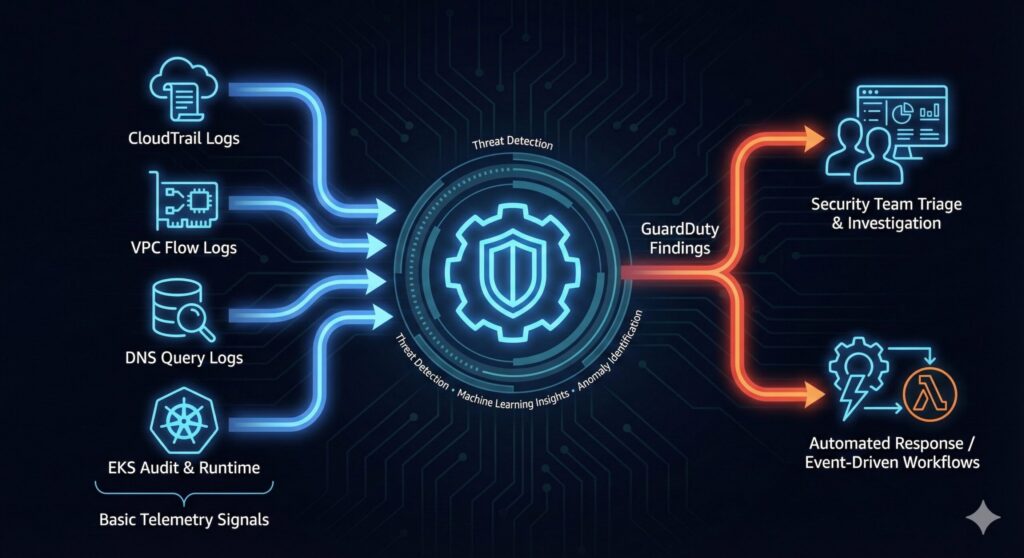
A simple explanation is that GuardDuty findings are the transformation of basic telemetry signals into analysis, threat detection, and anomaly identification. These telemetry signals include CloudTrail, VPC Flow Logs, DNS Logs, and EKS runtime events. These telemetry signals ultimately feed into monitoring systems such as CloudWatch metrics and dimensions, enabling operational visibility and alerting. GuardDuty also applies machine-learning-driven insights that detect suspicious behavior not visible through manual log review. They also serve as the foundation for triage and response, guiding security teams on where to investigate and what actions to automate.
How Misconfigurations Lead to Missed or Incomplete Findings
However, poor configuration can limit GuardDuty findings’ ability to analyze activity across the full AWS footprint due to disabled regions or accounts. Another issue is when incomplete data sources reduce visibility, such as missing CloudTrail, DNS, or VPC Flow Logs. Also, implementing overly broad suppression rules can hide legitimate findings and mask early indicators of compromise.
Explaining Why Understanding GuardDuty Findings Matters
GuardDuty findings directly translate into AWS threat visibility, enabling rapid response and helping to secure the AWS environment. However, misconfiguring them weakens detection and increases the vulnerability of AWS resources.
Findings Drive Security Visibility and Response
AWS threat visibility is improved by centralizing detection signals that highlight suspicious or anomalous activity across AWS accounts. This also includes prioritization cues that assist teams or processes in triaging high-risk behaviors requiring immediate attention. GuardDuty findings also enable triggering for automated responses by enabling rapid containment through event-driven workflows. In addition to response enablement, it provides context for subsequent investigation by linking resources, actors, and behavioral patterns.
Misconfigurations Lead to Blind Spots
Blind spots in GuardDuty findings are seriously dangerous since that is where bad actors can thrive, including unmonitored regions or accounts where they are not enabled. Also, reducing the scope of the analyzed activity can mask threats when telemetry sources are missing. Significantly, poorly configured suppression rules can hide alerts that serve as an early warning for attacker behavior. However, the most insidious misconfiguration is gaps in multi-account deployments, leaving uncovered areas in the environment and an opening for attackers.
Once you understand how GuardDuty findings are generated and classified, the next step is operationalizing them. For guidance on tuning, response workflows, and production-grade usage, see AWS GuardDuty Best Practices.
Mistake #1 — Not Enabling GuardDuty in All Regions
Not enabling GuardDuty in all regions limits findings only to certain regions, masking malicious actors.
Why Attackers Target Unmonitored Regions
Unmonitored regions create low-visibility zones where security teams and processes are far less likely to notice or detect any rogue activities. This allows malicious actors to deploy resources such as EC2 instances or to abuse IAM without triggering alerts and escaping attention. Therefore, they can exploit forgotten or unused regions that lack GuardDuty or other monitoring controls. Furthermore, they test their malicious actions safely, knowing that detection gaps reduce the risk of containment.
Why GuardDuty Findings Still Matter Even Without Active Workloads
GuardDuty generates findings from account-level telemetry analysis, capturing CloudTrail, DNS queries, and IAM activity even when no resources are running. They also enable credential misuse detection, as threat actors can exploit compromised IAM keys across regions regardless of workload presence. Additionally, they provide early warning of unauthorized resource creation, such as rogue EC2 or Lambda deployments in previously unused regions. By providing continuous monitoring coverage, they ensure there are no gaps for attackers to operate in, as nothing is deployed there.
How to Fix This Regional Blind Spot
It follows that enabling GuardDuty in all regions, including unused or rarely accessed regions, will reduce gaps for malicious actors. This is easily achieved by using AWS Organizations auto-enablement, which ensures child accounts inherit full regional coverage. Moreover, security teams should automate compliance checks to detect and remediate disabled regions using Config rules or EventBridge workflows. Finally, since AWS is continually launching new regions, security governance should audit the regional status regularly.
Mistake #2 — Missing or Misconfigured Data Sources
Missing data explains why GuardDuty findings are less effective and makes the AWS environment vulnerable.
Common Gaps in GuardDuty Data Sources
There are some common oversights that result in gaps around GuardDuty Data Sources, limiting its findings. Disabling or partially scoping CloudTrail can limit visibility into API and IAM activity, missing important signals around malicious activities. This extends into missing VPC Flow Logs, where data pointing to nefarious activities is lost from key VPCs, subnets, or traffic types. Also, failing to enable DNS query logging will reduce insights into suspicious domain resolution. Moreover, when these data sources have incomplete coverage across accounts or regions, this creates uneven detection visibility, presenting opportunities for bad actors.
Enabling and properly configuring core telemetry sources like CloudTrail, VPC Flow Logs, and DNS logging is essential — for a deeper look at comprehensive logging and monitoring practices, see our AWS Logging and Monitoring Guide.
How Missing Data Impacts GuardDuty Findings
Having missing data will reduce the behavioral context, limiting GuardDuty’s ability to correlate events accurately. This also results in missed detection patterns due to isolated signals failing to meet finding thresholds, reducing GuardDuty’s effectiveness. Incomplete data also creates blind spots across networks and API activity that allows suspicious behavior to go undetected. Accordingly, this lowers confidence or yields incomplete findings, weakening prioritization and response decisions.
How to Fix Data Source Misconfigurations
Upon identifying missing or misconfigured data, it is imperative to address this immediately. As a must, it is imperative to enable CloudTrail organization-wide to ensure consistent monitoring of all accounts and regions. For CloudTrail configuration patterns that improve security and operational visibility, see our AWS CloudTrail Best Practices article. It is also vital to activate VPC Flow Logs for all critical VPCs, including relevant traffic types and retention settings. Furthermore, ensuring that DNS logging is enabled will provide visibility into domain resolution behavior. But importantly, regularly validate data source coverage to protect against missing data in the future. Engineers can do this via the GuardDuty console, AWS Config rules, or automated checks.
Mistake #3 — Misunderstanding GuardDuty Finding Severity
Here, we explain common misconceptions around GuardDuty Findings’ severity and how to avoid them.

Low Severity Does Not Mean Low Risk
This is a core misconception since low-severity findings often represent early-stage attacker behavior, just like in the world of espionage. On the contrary, we should regard these as reconnaissance indicators such as scanning, enumeration, or probing behavior. Therefore, we should not ignore early IAM misuse signals that include unusual API calls or credential testing. This also includes container or workload probing that often precedes lateral movement. Additionally, we should identify precursor activity patterns that usually appear before escalation to higher-severity findings.
Why Teams Underestimate Low-Severity Findings
Obviously, there are compelling reasons why teams underestimate GuardDuty’s low-severity findings. The most common reason is alert fatigue, which leads teams to ignore low-severity findings routinely. Associated with this is severity bias, where teams focus only on high or critical alerts and ignore alerts that warn of an impending attack. Another valuable consideration is that findings are reviewed in isolation rather than as patterns masking their significance. Also, teams fail to understand GuardDuty’s severity model and assume that severity equals impact rather than the attack stage.
How to Correct Severity Misinterpretation
Firstly, there should be an early-warning mindset akin to the world of espionage that treats low-severity findings as signals for preventative action. Accordingly, teams should perform trend analysis of low-severity findings to identify recurring patterns over time. Another valuable practice is to perform contextual grouping by correlating findings by resource, identity, or source IP. Additionally, they should implement severity-aware routings that escalate repeated low findings when their thresholds are crossed. Teams can either partially or fully automate these processes.
Mistake #4 — Overusing Suppression Rules
Suppression rules are necessary given that many GuardDuty findings result in noise; however, issues arise when they are not applied correctly.
The Danger of Suppressing GuardDuty Findings Too Broadly
Broad suppression rules can potentially hide many events that are indicators of early-stage attacker behavior, similar to misunderstanding severity. A clear example of this is when suppression rules hide credential compromise indicators. Additionally, they mask port-scanning, brute-force attempts, or data-exfiltration signals pointing to attackers. However, the mindset here is that security teams regard suppression as silencing rather than precision tuning.
Why Suppression Rules Are Commonly Misused
There are many parallels here to misunderstanding severity levels in the previous section, with the top issue of alert fatigue driving aggressive suppression. There is also pressure, usually from management, to “clean dashboards” instead of a focus on signal quality. Furthermore, teams often do not understand the value of finding context and recurrence with interpreting GuardDuty findings. Another danger requiring regular reviews is creating suppression rules but never revisiting them.
GuardDuty Suppression Rules Best Practices
Suppression rules are essential to reduce noise, but following best practice will optimize GuardDuty findings for security teams. Primarily, security teams should suppress only deterministic, well-understood noise. Correspondingly, teams must scope rules tightly by resource, IP, or finding type and actively ensure suppression rules are not too broad. In order to prevent rules disappearing from view, security teams should regularly review and expire suppression rules. Moreover, they should adopt the mindset that suppression rules are there to reduce noise but not hide risk.
Mistake #5 — Not Automating GuardDuty Triage and Response
As explained previously, there are several misconfigurations for GuardDuty findings, but a common thread is the need for automation.
Why Manual Review Fails at Cloud Speed
In many areas of the security landscape, automation with manual oversight is mandatory, given the instantaneous unfolding of security events. This is continually escalating with EC2 crypto-mining and resource abuse spreading rapidly. Another example is IAM key compromise escalating across services and regions, demanding an automated response. The allowed time gap between detection and containment to prevent damage is continually decreasing. Manual response cannot match it. Also, attackers purposely exploit response latency because that is their only window of opportunity.
The Risk of Delayed or Inconsistent Response
Given that teams must automate responses to GuardDuty findings, failure to do so results in serious consequences. Since analysts are under pressure, they are unlikely to make consistent decisions in findings response. Relatedly, repeatable attack patterns are not stopped early due to the inability to identify these patterns under pressure. Also, since isolation of resources is relatively slower than the corresponding blast radius increases, putting more resources at risk. Finally, security teams become bottlenecks in timely response to GuardDuty findings.
How to Automate GuardDuty Findings and Response
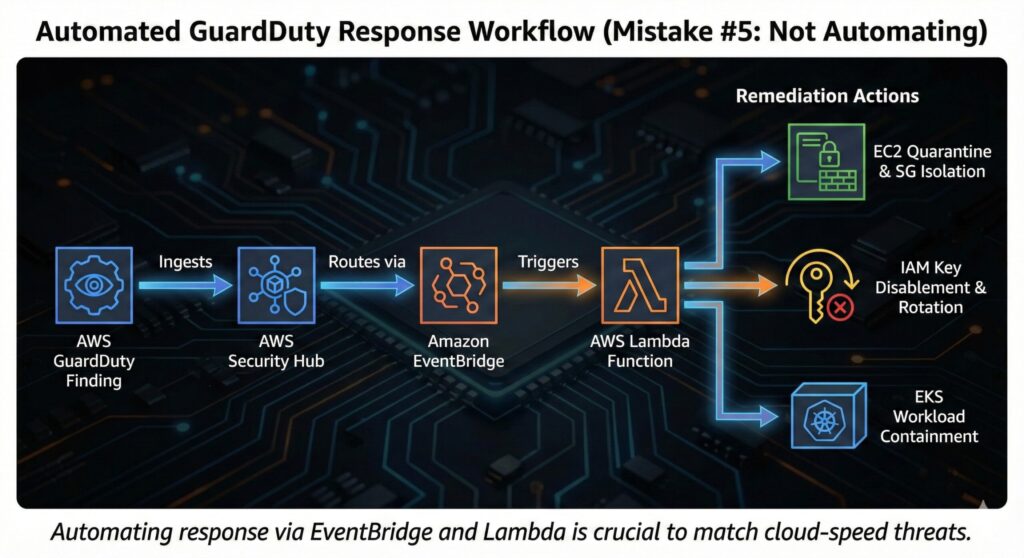
There are several common automated GuardDuty findings responses that teams can implement immediately. They can implement automated EC2 quarantine and security group isolation to instantly curtail the threat. Also, automating IAM access key disablement and rotation will significantly help secure the environment. This also extends to EKS workload and automatically containing them upon findings. Teams can implement these by configuring Security Hub to trigger EventBridge, which in turn triggers Lambda functions that perform these actions. Meanwhile, teams still must have guardrails in place to balance automation and human oversight.
Final Thoughts: Strengthening Your AWS Security Posture With Better GuardDuty Findings
Security teams must treat GuardDuty findings as actionable security signals, not just alerts, when securing any AWS environment. Therefore, misconfigurations are the primary source of detection failure in making the environment vulnerable, and not service limitations. Fundamentally, having full coverage across all regions, accounts, and data sources is a baseline requirement. Furthermore, handling early-stage findings, enforcing suppression discipline, and implementing automated findings response serve as indicators of security maturity. These will allow security teams and organizations to attain operational excellence through consistency, visibility, and timely response.
Further Reading
Official reference: See the AWS Documentation on Working with GuardDuty findings for the official finding format, fields, and workflow guidance.
Beginning AWS Security: Build Secure, Effective, and Efficient AWS Architecture by Tasha Penwell
AWS Security by Dylan Shields
Mastering AWS Security: Create and maintain a secure cloud ecosystem by Albert Anthony
AWS Certified Security Study Guide: Specialty (SCS-C02) Exam by Alexandre M. S. P. Moraes
Affiliate Disclosure: As an Amazon Associate, I earn from qualifying purchases. This means that if you click on one of the Amazon links and make a purchase, I may receive a small commission at no additional cost to you. This helps support the site and allows me to continue creating valuable content.