
AWS Security Hub Findings: Making Sense of Security Signals
AWS Security Hub Findings: Introduction AWS Security Hub findings address the issue of fragmented security signals from multiple independent AWS […]
AWS Security Hub Findings: Introduction AWS Security Hub findings address the issue of fragmented security signals from multiple independent AWS […]

Introduction To explain VPC Flow Logs, it is helpful to understand the problems they try to solve. AWS services generally

Is AWS GuardDuty a SIEM? Why This Question Keeps Coming Up To better understand whether AWS GuardDuty is a SIEM,

Introduction: GuardDuty Findings Explained Why GuardDuty Findings Are Central to AWS Threat Detection A simple explanation is that GuardDuty findings
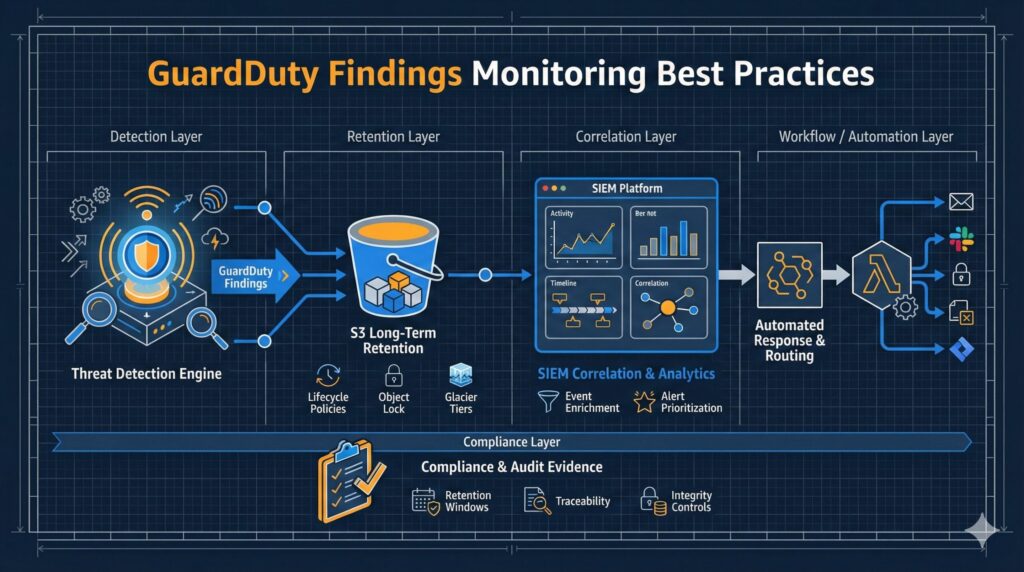
Introduction to GuardDuty Findings: Monitoring Best Practices GuardDuty findings are central to any security response workflow; therefore, best practices around
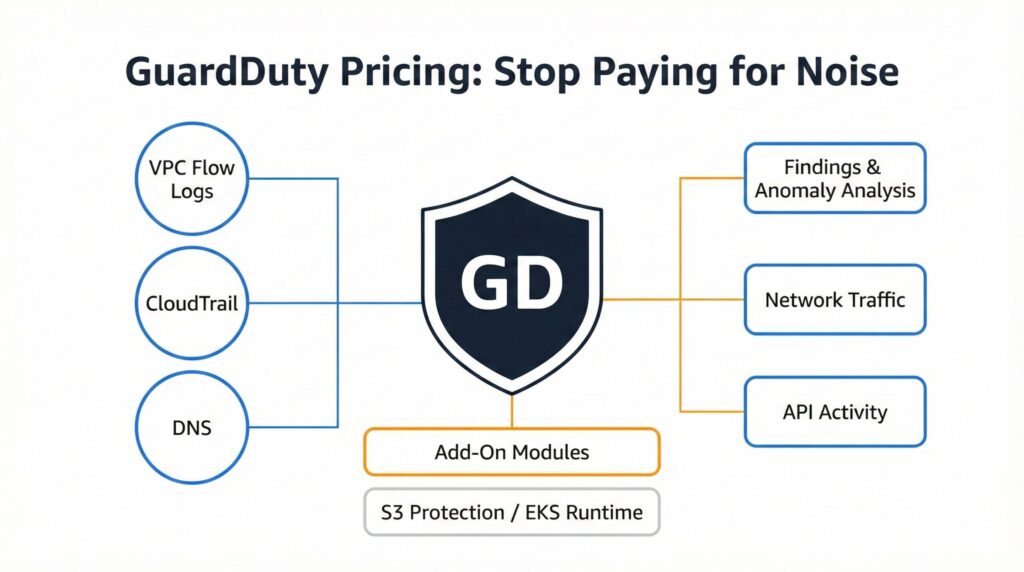
Introduction: Why GuardDuty Pricing Isn’t as Straightforward as It Looks We surveyed GuardDuty best practices, but pricing is of paramount

Best Practices: What Is AWS GuardDuty and Why It Matters AWS GuardDuty Best Practices takes over from AWS Logging and

CloudWatch Metrics Dimensions: Introduction to Best Practices Best practices in CloudWatch metrics contribute to a comprehensive view of the cloud
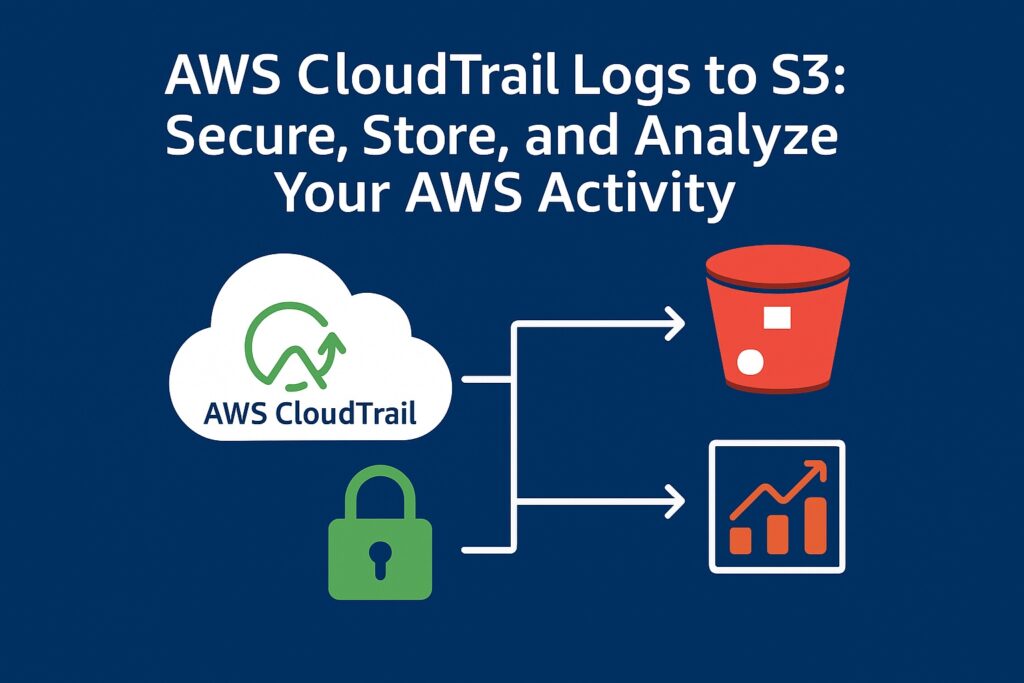
Introduction: AWS CloudTrail Logs to S3 AWS CloudTrail logs to S3 have the ability to track every API call and

Introduction: Why Logging and Monitoring Matter in AWS Logging and monitoring are the starting points for any security incident response